
Como avaliar a qualidade das pesquisas de opinião pública no Brasil?
By Neale Ahmed El-Dash on Aug 12, 2020
Neste post discutiremos quais são as principais estratégias para mensurar a opinião pública, e em específico como realizar pesquisas eleitorais. Existem 3 modos de entrevista principais: presencial, telefônica e online. Todas têm suas vantagens e desvantagens, as quais serão discutidas tanto do ponto vista teórico quanto prático.
Introdução
O objetivo desse post é explicar alguns conceitos técnicos de pesquisas de opinião pública para quem não trabalha na área de pesquisa. Esses conceitos são importantes para compreender como as pesquisas são realizadas, e como as decisões metodológicas feitas durante a execução dessas pesquisas podem afetar a sua qualidade. Espero que os conceitos discutidos nesse post ajudem tanto pessoas com o objetivo de produzir pesquisas, quanto quem utiliza dados de pesquisas, a entender a dificuldade de fazer pesquisas de opinião, os potenciais problemas que podem ocorrer e quão bem a opinião pública pode ser representada por essas pesquisas.
Para atingir esse objetivo, a discussão será razoavelmente técnica, porém em português. Não utilizarei nenhuma fórmula matemática. Quem é da área de exatas sabe que uma fórmula é como uma imagem, “vale por mil palavras”. Então explicar esses conceitos sem recorrer a elas não é fácil. Este post é a minha tentativa de explicar alguns desses conceitos complexos de forma simples, quem sabe até intuitivamente em alguns casos. Como consequência dessa opção, o post é, de fato, bastante longo. A maioria das ideias apresentadas aqui também são discutidas, de forma mais técnica, com fórmulas, na minha tese de doutorado.
Apesar de ter escrito esse texto como um post, com começo, meio e fim, entendo que muitos dos leitores prefiram utilizá-lo como uma referência para compreender aspectos técnicos específicos das pesquisas, lendo somente seções sobre o tema de interesse. Para facilitar esse tipo de uso do post, abaixo apresento um índice, com links para facilitar o acesso as diferentes seções:
A opinião pública pode ser definida como sendo as atitudes, os desejos, os pensamentos da maioria das pessoas. É a opinião coletiva das pessoas de uma sociedade ou país com relação a um assunto ou problema. Ela é dinâmica, influenciável e multifacetada. E ela é complexa de ser medida. Pesquisas de opinião-pública tentam mensurar essa opinião coletiva. O que torna as pesquisas de opinião tão importantes nos dias de hoje é o fato delas permitirem o entendimento do comportamento de toda a população de interesse (a população alvo), apesar de entrevistar apenas alguns poucos milhares de pessoas (a amostra). As pessoas pesquisadas (pertencentes à amostra) usualmente respondem a questionários, ou formulários, ou são entrevistadas sobre o tema de interesse. Após coletadas, as informações são utilizadas para explicar a opinião de todas as pessoas da população alvo, e não somente daquelas pessoas pertencentes à amostra.
Essas pesquisas usualmente são realizadas por firmas especializadas, conhecidas como instituos de pesquisa. Esta especialização ocorre porque, para obter resultados confiáveis dentro de um prazo estipulado, é necessário planejamento e execução cuidadosos, pois vários aspectos são cruciais para que a pesquisa possa representar a opinião pública corretamente.
As pesquisas de opinião são úteis em muito contextos. No mundo corporativo é importante conhecer estas opiniões para desenvolver um produto que o consumidor gosta e compra, descobrir se ele está satisfeito com uma empresa, ou se ele compra produtos da concorrência; no meio acadêmico existe o interesse em entender como as pessoas pensam e como elas reagem a determinadas situações; durante as eleições é importante para os candidatos entenderem quais são as necessidades e desejos do eleitorado para que possam definir suas plataformas de governo.
Talvez o tipo de pesquisa de opinião pública de maior visibilidade sejam as pesquisas eleitorais, que têm como objetivo saber como a população votará em uma eleição. Elas também são, geralmente, as de maior dificuldade de execução, pois têm prazos muito curtos para serem realizadas. Além disso, os resultados dessas pesquisas são muito sensíveis, pois impactam diferentes interesses políticos. Quando pesquisas eleitorais são divulgadas na mídia, o público conhece qual candidato têm a preferência do eleitorado naquele determindado instante de tempo, permitindo que essa informação seja usada na escolha racional de um candidato. Além disso, elas também afetam aos candidatos e às suas campanhas, seja pela confiança e exposição na mídia adquiridas por os que estão na liderança, ou pela desmotivação daqueles que não têm chances reais de ganhar a eleição. Pesquisas eleitorais, mesmo quando não divulgadas na imprensa, também servem para poder auxiliar os candidatos a definirem suas estratégias de campanha e suas plataformas de governo, ao conhecer as principais preocupações da população e entender quais áreas sócio-econômicas são prioridades do eleitorado. Por causa do papel central que as pesquisas eleitorais têm no mundo das pesquisas de opinião, nesse post daremos um destaque especial a elas.
Existe muita polêmica com relação às pesquisas eleitorais realizadas no Brasil. Essa polêmica é fruto, em parte, da grande exposição na mídia que essas pesquisas recebem durante os ciclos eleitorais (de 2 em 2 anos), pelo fato desse ser um dos únicos cenários reais onde é possível avaliar se pesquisas de opinião conseguiram “prever corretamente”1 o resultado da eleição e pelos diversos interesses políticos envolvidos. Por causa da importância e do potencial impacto que as pesquisas eleitorais podem ter nas eleições e no futuro do país, à divulgação das mesmas na mídia é regulamentada pelo Tribunal Superior Eleitoral (TSE). A legislação atual, no que diz respeito a divulgação das pesquisas eleitorais no ano de 2020, pode ser lida nesse link.
A estatística é muito importante no planejamento e interpretação dos resultados das pesquisas eleitorais. Exista uma áera específica da estatística que estuda o processo de seleção de apenas uma PARTE da população (amostra) de forma que seja possível tirar conclusões sobre TODA a população (alvo), a amostragem. Do ponto de vista dos estatísticos, também há muita polêmica sobre as pesquisas eleitorais. Ela surge porque as metodologias utilizadas pelos institutos de pesquisa tendem a se preocupar principalmente com o lado prático da pesquisa; já os acadêmicos tendem a se preocupar apenas com a teoria. Não é possível fazer boas pesquisas eleitorais ignorando a teoria, porém também não é possível fazê-las sem considerar o aspecto prático. Citando uma frase do filósofo John Dewey: “A prática sem a teoria é cega. E a teoria sem a prática é vazia”.
Existem três modos de entrevista principais usados no Brasil para realizar pesquisas de opinião pública. O modo de entrevista se refere à forma como as pessoas pertencentes à amostra são contactadas e entrevistadas. Cada modo tem características bastante específicas, as quais serão descritas brevemente a seguir:
- Presencial: Pesquisas presenciais são realizadas pessoalmente por um entrevistador. Elas podem ser feitas nos domicilios ou em pontos de fluxo. Se desejado, o controle geográfico desse tipo de pesquisa pode ser muito refinado, chegando até o nível do bairro (dependendo da cidade). Pode ser aplicado um questionário de papel ou eletrônico.
- Telefônica: Pesquisas por telefone tabmém são realizadas por um entrevistador. Elas podem ser feitas por entrevistadores humanos ou URA’s (Unidade de Resposta Audível); Os sistemas URA podem responder com áudio pré-gravado ou dinamicamente gerado para entrevistar os respondentes. O controle geográfico geralmente é no nível da área do DDD. Podem ser no nível do município, porém essa resolução geralmente implica no aumento do custo e tempo de execução da pesquisa.
- Online: Pesquisas também podem ser realizadas no computador ou celular pelo próprio respondente. Os respondentes podem ser recrutados para participar da pesquisa pela internet, mas isso requer uma presença online maior do respondente. O uso de respondetes não conectados pode tornar a pesquisa mais abrangente, porém o recrutamento será mais complicado. O nível de controle geográfico depende das informações disponíveis, porém geralmente chega-se somente ao nível do estado. Essas pesquisas tendem a ser mais rápidas e baratas do que as realizadas pelos outros modos.
Além das diferenças metodológicas mencionadas acima, os três modos de pesquisas também são muito diferentes com relação à logística da coleta de dados, fato que afeta muito o custo total da pesquisa e também o tempo necessário para completar as entrevistas desejadas. Estas diferenças, e outras que serão discutidas no resto deste post, tornam a escolha do modo de entrevista (pelo contratante) muito difícil: é necessário encontrar um equilíbrio entre o custo da pesquisa, o prazo para a coleta dos dados e a precisão das estimativas. Dependendo do objetivo da pesquisa, da população alvo, do tipo de questionário desejado e da precisão necessária, diferentes modos de pesquisa podem ser recomendados.
Neste post discutiremos com algum detalhe, tanto aspectos práticos quanto teóricos, das três etapas principais na realização de uma pesquisa de opinião pública: o planejamento da pesquisa, a coleta dos dados (execução) e a análise dos dados. Na discussão sobre cada etapa será dada atenção especial aos aspectos específicos de cada um dos modos de entrevista citados anteriormente.
A) Planejamento de pesquisas de opinião-pública (e os tipos de erros a serem evitados)
Não é fácil planejar uma pesquisa de opinião-pública, pois existem muitos fatores importantes que determinarão a efetividade da pesquisa em mensurar a opinião-pública. Decisões têm que ser tomadas em todos os estágios da pesquisa, as quais podem ser fundamentais para que a pesquisa tenha a performance desejada num prazo aceitável. Mais que isso, não é possível desenhar e executar uma pesquisa sem buscar um balanço entre qualidade do resultado e custo da pesquisa. Independentemente de todas essas questões, não é possível fazer uma boa pesquisa sem planejamento. O planejamento é essêncial em todos os estágios da pesquisa: antes, durante e depois da coleta de dados.
Para planejar uma pesquisa de forma eficiente, é preciso compreender diferentes fatores relavantes em cada etapa, bem como conhecer os erros que podem ocorrer em função das decisões metodológicas que serão tomadas. Uma das grandes dificuldades é que a maioria das etapas exige a participação de profissionais de diferentes áreas. Sem bastante experiência prática e conhecimento teórico, é muito difícil compreender a complexidade e a profundidade de todos os aspectos relevantes para se realizar uma pesquisa de opinião-pública de qualidade.
Uma das precauções a serem tomadas ao planejar uma pesquisa é tentar evitar erros (e o viés que potencialmente introduzem na pesquisa). As fontes de erro mais comuns em pesquisas de opinião pública podem ser classificadas em duas grandes categorias, os erros de observação e não-observação. Na figura abaixo são resumidas as possíveis fontes de erro usualmente consideradas em uma pesquisa.
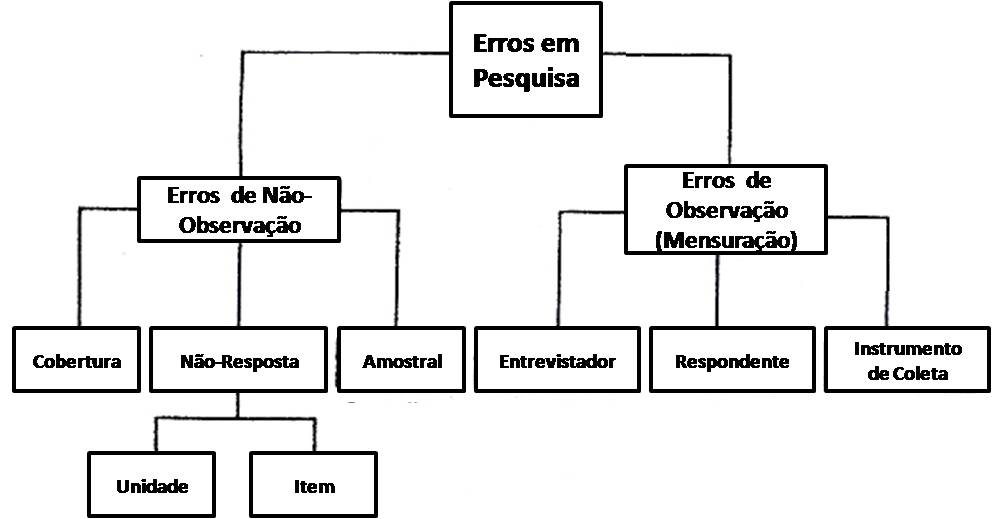
Tipos de erros em pesquisa
a1) Erros de observação
Os erros de observação então, no geral, se referem à mensuração inadequada da opinião dos respondentes. Podem ser resultado de problemas com o questionário, como também do comportamento do entrevistador ou do próprio respondente. Apesar desses tipos de erro influenciarem bastante a qualidade dos resultados, e a importância de considerá-los ao se planejar uma pesquisa, eles envolvem pouco a estatística e fogem do escopo desse post. Vamos listar abaixo as principais fontes desse tipo de erro, porém não entraremos em muito detalhes sobre cada um.
- Questionário (Instrumento de coleta): Erros de observação podem occorer se o questionário for mal formulado, de maneira a não permitir que uma pessoa responda e/ou compreenda a pergunta corretamente. Por exemplo, se é perguntado ao respondente se “o seu posicionamento político é de esquerda ou direita?” e o respondente não entender os extremos desse espectro político, ou não se situar em algum dos extremos, não conseguirá responder corretamente à essa pergunta. Aspectos psicométricos são bastante relevantes para que a opinião de uma pessoa consiga ser captada por perguntas em um questionário. O tipo e a simples ordem podem alterar a resposta do respondente. É diferente ser questionado sobre intenção de voto quando o respondente precisa fornecer espontaneamente o nome do candidato (intenção de voto espontânea) do que quando deve escolher uma opção de uma lista de candidatos disponíveis (intenção de voto estimulada). As respostas de uma pessoa aos dois tipos de pergunta podem ser diferentes, principalmente pelo desconhecimento dos candidatos pelo respondente, mas também por questões como a quantidade e a ordem com que os candidatos são apresentados, a explicitação dos partidos ao lado dos nomes dos candidatos e a inclusão do apelido dos candidatos, entre outros motivos. O enunciado de perguntas localizadas antes de uma pergunta de intenção de voto no questionário pode alterar a resposta do respondente, principalmente se elas versam sobre assuntos referentes aos candidatos/partidos, como conhecimento, popularidade ou corrupção. Fica claro então que questões aparentemente sutis podem alterar bastante o resultado da mensuração da opinião de uma pessoa.
- Entrevistador: O entrevistador pode induzir a resposta do respondente ou simplesmente não aplicar corretamente o questionário (com ou sem intenção). O entrevistador também pode fraudar a pesquisa, seja inventando respostas, entrevistando uma pessoa diferente daquela selecionada para estar na amostra, ou pulando perguntas no questionário para reduzir o tempo total da entrevista. Muitas vezes, define-se antes da pesquisa um percentual de entrevistas que serão verificadas por uma outra pessoa, checando se as mesmas respostas são dadas pelo respondente às mesmas perguntas, com o objetivo de inibir a ocorrência de fraudes.
- Respondente: O prórpio respondente pode responder equivocadamente (com ou sem intenção). Ele pode não querer informar, por exemplo, a sua renda ou ter medo ou vergonha de responder corretamente (como em questões pessoais sobre sexualidade ou saúde ou em situações onde existe um lado “politicamente correto”, nesse caso conhecido, em inglês, como Social desirability bias). Além disso, algumas pessoas têm personalidades aquiescentes, sendo mais propensas a concordarem com declarações do que discordarem - independentemente do conteúdo. Freqüentemente, essas pessoas vêem o entrevistador como um especialista, o que faz com que seja mais provável que elas reajam positivamente à qualquer pergunta mesmo que ele não esteja realmente de acordo (viés de simpatia ou em inglês satisficing bias). As vezes o respondente até acha que está dando informações corretas, mas erra porque desconhece algo (de outro morador do domicílio, por exemplo).
a2) Erros de não-observação
Embora erros de observação sejam importantes numa pesquisa de opinião pública, e por isso foram incluídos neste post, do ponto de vista estatístico, a discussão mais interessante está relacionada a medir a opinião-pública da população, e não a opinião de uma pessoa. São os erros de não-observação que se mostram mais relevantes no planejamento de uma pesquisa de opinião-pública, porque eles estão relacionados, implicita ou explicitamente, à seleção dos respondentes que participarão na pesquisa. Estes erros determinam quais pessoas pertencerão efetivamente à amostra (e podem levar ao enviesamento dos resultados). São três os tipos principais de erros de não-observação.
- Amostral: O erro amostral ocorre porque apenas algumas pessoas são selecionadas para participar da pesquisa. Praticamente toda pesquisa de opinião pública terá um erro amostral associado a ela, pois a pesquisa é baseada em uma amostra da população alvo, enquanto os seus resultados são generalizados para toda a população. O erro amostral observado pode ser definido como a diferença média (ignorando o sinal) entre a resposta das pessoas na pesquisa e a de todas as pessoas da população (se esta quantidade fosse conhecida).
- Cobertura: Erros de Cobertura ocorrem quando pessoas são excluídas da população a qual pertencem, consequentemente não tendo chances de pertencer à amostra. Isso geralmente ocorre quando as listagens utilizadas para selecionar as amostras estão incompletas ou desatualizadas. Por exemplo, em pesquisas telefônicas, pessoas sem telefone são excluídas da pesquisa. Similarmente, em pesquisas online, pessoas sem acesso à internet não podem participar das pesquisas. Esse tipo de erro também ocorre em pesquisas presenciais, muitas vezes por escolha dos responsáveis pela pesquisa. É comum não incluir na amostra áreas rurais muito afastadas, ou até mesmo favelas, como forma de reduzir o custo da pesquisa.
- Não-Resposta: O erro de não-resposta ocorre quando não se consegue mensurar as opiniões de interesse (perguntas) de pessoas selecionadas para pertencer à amostra. São dois tipos de falta de resposta: não-resposta da unidade, quando nenhuma das perguntas do questionário è mensurada e não-resposta do item, quando algumas das perguntas (ou itens) não são mensuradas. A não resposta da unidade é resultado de não conseguir respostas dos respondentes desejados, ou por não encontrá-los (endereço errado, telefone errado, domicílio de residência vazio, entre outros motivos) ou pela recusa das pessoas em responder (não atende a campainha ou o telefone, ou depois de atender, se recusar a participar da pesquisa, entre outros motivos). A não-resposta do item ocorre quando uma pessoa se recusa a responder a uma pergunta (item) específica, como é frequente com as perguntas sobre renda. É comum, por exemplo, que pelo menos 20% dos respondentes não respondam a uma pergunta aberta sobre valor do seu salário, ou o informa errado.
A descrição dos erros acima é superficial, e tem o objetivo apenas de pontuar os tipos de erros existentes, das mais variadas fontes, que podem ocorrer em pesquisas de opinião pública. Mesmo num mundo ideal, onde o questionário é claro e bem desenhado, onde os entrevistadores são bem treinados, onde os respondentes são facilmente encontrados e honestos, onde a amostra é selecionada usando listagens novas e abrangentes de forma a minimizar o erro amostral, haverão erros e vieses na pesquisa. Do ponto de vista prático, esses erros são inevitáveis. É impossível prever exatamente qual será o efeito total da soma de todos os erros nas estimativas das pesquisas. É comum se referir ao efeito cumulativo de todos esses erros como viés metodológico. Esse nome se refere à metodologia utilizada para fazer a pesquisa, pois ela envolve diversas decisões em todas as etapas da pesquisa, as quais têm como consequência erros como os discutidos acima.
B) Execução de pesquisas de opinião (Amostragem na prática)
Existe toda uma teoria da estatística, denominada amostragem, desenvolvida justamente para determinar qual a maneira mais eficiente de selecionar as pessoas para uma amostra de forma a permitir que conclusões sejam possíveis para toda a população alvo. A teoria desenvolvida nessa área pressupõe que o estatístico tem controle total sobre a seleção das pessoas para participar de uma pesquisa. Na prática, dado os erros de não-observação, pode-se argumentar que são estes erros que são responsáveis por determinar efetivamente quais pessoas pertencerão à amostra observada da pesquisa.
O erro amostral tem explicitamente o papel de quantificar a diferença entre uma amostra selecionada e a população inteira. É o foco principal da amostragem, porém na prática, os erros de cobertura e de não-resposta também acabam implicitamente alterando o desenho amostral ideal em dois aspectos fundamentais. Primeiramente, a abrangência da pesquisa acaba sendo determinada pelo erro de cobertura. Dependendo do modo de entrevista escolhido, a população alvo acaba sendo efetivamente alterada. Ou seja, apesar da população alvo usualmente ser especificada ao definir o escopo do projeto, a escolha de como entrar em contato com os respondentes acaba alterando qual população pode de fato ser selecionada para participar da pesquisa. Em segundo lugar, após a amostra ter sido selecionada para representar a população alvo da melhor maneira possível, o erro de não-resposta faz com que as pessoas efetivamente entrevistadas não sejam as mesmas que haviam sido selecionadas durante a etapa de amostragem. Se esse mecanismo de não-resposta não for controlado, ele pode afetar bastante o resultado da pesquisa, embora a definição de cotas (a ser discutido nessa seção) durante a coleta dos dado seja uma maneira de ajudar a controlar esse erro.
Fica claro que é importante discutir com mais profundidade como amenizar esses erros na seleção da amostra, a qual, obviamente, é fundamental para permitir que possamos analisar a opinião de todas as pessoas do universo alvo, e não somente da amostra. Mais que isso, como esses erros não estão sob controle dos pesquisadores, torna-se mais essencial ainda a etapa de análise dos resultados (nessa seção), pois na prática além dela extrapolar os resultados da amostra, ela também pode corrigir muitos dos erros de cobertura e de não-resposta.
Como acabamos de ver, erros de não-observação são muito importantes na definição da amostra efetivamente observada. Neste post vamos dividir a discussão da coleta de dados em relação aos efeitos desses três tipos de erros fundamentais: erro amostral, erro de cobertura e erro de não-resposta. Usualmente essa não é a forma como esse tema é apresentado, mas eu acredito que dessa forma fica mais claro que é impossível separar o erro amostral, o qual está sob controle do estatístico, dos outros erros de não-resposta, os quais não estão sob seu controle.
b1) Amostragem: a impossibilidade de entrevistar todas as pessoas
O Brasil tem hoje uma população de aproximadamente 210 milhões de pessoas. Se todas as vezes que houvesse interesse em saber a opinião dos brasileiros sobre algum assunto fosse necessário entrevistar a todos, não poderíamos saber a opinião-pública sobre nenhum tema. Não saberíamos as opiniões dos brasileiros sobre política, religião, saúde, educação, trabalho, qualidade de vida ou lazer. Não saberíamos quanto foi a inflação no mês passado; não saberíamos quanto é o desemprego atualmente; não saberíamos quantas crianças deixam de ir para escola; não saberíamos quantos corinthianos existem. Em relação à grande parte da nossa vida, seríamos “surdos”. O único momento onde saberíamos a nossa opinião coletiva seria em eleições e plebiscitos, que ocorrem de 2 em 2 anos, e no censo, que ocorre a cada 10 anos.
Felizmente, não somos coletivamente surdos, pois não é necessário ouvir 210 milhões de vozes para compreender qual é a opinião pública. Dependendo da precisão desejada, algumas centenas de vozes bem escolhidas são suficientes para ouvir a nossa sociedade. Nessa seção discutiremos com mais detalhes a área da estatística especializada em ouvir as vozes de toda população, porém utilizando para isso apenas uma pequena amostra de pessoas: a amostragem.
O objetivo desta seção não é discutir os conceitos da amostragem em profundidade, menos ainda utilizar fórmulas e conceitos técnicos. É para discutir dois aspectos principais que precisamos considerar em pesquisas de opinião-pública: erro amostral e estratificação. O erro amostral é um conceito incrivelmente difícil de ser explicado com palavras, mas vou tentar fazer justamente isso, porém a explicação pode ser cansativa. Se o leitor quiser pular esta seção, é suficiente compreender que quando analisamos os resultados de somente uma amostra de pessoas, é necessário acrescentar uma medida de incerteza aos resultados, a margem de erro, para falar da opinião de todos. Isso se faz necessário pois não temos certeza sobre a opinião de cada pessoa na população. Quanto mais incerteza existe sobre a opinião-pública, maior será a margem de erro (o famoso +/- x%).
O segundo aspecto a ser discutido é a estratificação geográfica da amostra, a qual implicitamente também controla aspectos sócio-económicos da população sendo estudada. Ou seja, como escolher nesse país de dimensões continentais, as pessoas que participarão da nossa amostra para representar de forma mais efetiva a opinião do brasileiro. Efetivo nesse contexto quer dizer com mais precisão, e com menos margem de erro. A forma como a amostra é escolhida pode aumentar bastante a efetividade da pesquisa, reduzindo gastos e permitindo também que possamos mensurar a opinião de áreas menores.
O que é o Erro amostral?
É difícil compreender o real significado de erro amostral, principalmente sem utilizar conceitos e fórmulas matemáticas. É também difícil de explicar o seu significado, em bom português, para leigos. Porém o conceito é importante para que o leitor possa entender como os erros podem ser quantificados ao se fazer pesquisas de opinião, e também entender as suposições necessárias para que esses erros sejam estimados. Caso o leitor queira entender o conceito de erro amostral com mais profundidade (e mais matemática), veja esse post sobre Pesquisas eleitorais e a Margem de Erro (Tutorial), o qual escrevi alguns anos atrás.
Como mencionamos anteriormente, pesquisas de opinião pública são feitas entrevistando apenas algumas centenas (ou milhares) de pessoas. Essas pessoas efetivamente entrevistadas compõem a amostra observada. Se o objetivo da pesquisa fosse apenas conhecer a opinião dessas pessoas entrevistadas, não haveria erro amostral, pois todas as pessoas da qual gostaríamos de saber a opinião teriam sido entrevistadas. Saberíamos exatamente quantas pessoas concordam com a frase A, quantas dizem que votarão no político B ou quantas estão satisfeitas com a marca C.
Entretanto, quase nunca o objetivo é conhecer apenas a opinião de quem foi entrevistado (da amostra), pois geralmente o interesse é saber a opinião da população alvo. O erro amostral só passa a existir quando usamos uma amostra de pessoas para tentar compreender a opinião de toda a população de interesse. Por exemplo, quando é realizada uma pesquisa eleitoral com 1000 pessoas de 16 anos ou mais, o interesse é em conhecer a intenção de voto de toda a população brasileira com 16 anos ou mais. Mas como é possível saber a opinião de todas as pessoas da população alvo, incluindo as pessoas que não foram entrevistadas? É possível saber quantas pessoas da população concordam com a frase A, quantas dizem que votarão no político B ou quantas estão satisfeitas com a marca C?
Pode parecer para o leitor que essa generalização é impossível de ser feita com sucesso, porém existem diferentes argumentos estatísticos que podem ser utilizados para justificar esse caminho lógico. Esses argumentos podem ser interpretados tanto uma receita de como a amostra deve ser selecionada, como também quais as suposições necessárias para que se possa generalizar os resultados da amostra. Discutirei aqui apenas o argumento mais comummente utilizado, conhecido como amostragem probabilística. Nessa linha de racioncínio, se faz uma única suposição básica: de que a probabilidade de cada pessoa da população alvo pertencer à amostra é conhecida (e positiva).
Nesse contexto, isso quer dizer que tem que ser possível para todas as pessoas participarem da pesquisa, e, além disso, que saibamos qual é a chance da participação de cada uma delas. Podemos citar um exemplo trivial. Se existir uma listagem com os nomes de toda a população, uma amostra probabilística poderia ser selecionada jogando uma moeda para decidir se cada pessoa participaria da pesquisa ou não. Neste exemplo, cada pessoa tem uma probabilidade de 50% de participar da pesquisa. E assim, a amostra efetivamente selecionada seria definida jogando uma moeda para cada nome da lista, e todas as pessoas em que a moeda resultou em cara participariam da pesquisa.
Desse exemplo deve ficar claro que cada vez que for selecionada uma amostra probabilística da mesma população, a amostra observada provavelmente seria diferente. Como diferentes pessoas podem ser selecionadas em cada amostra, e cada pessoa tem a sua própria opinião, cada amostra observada pode ter um número diferente de pessoas que concordariam com a frase A, que diriam que votariam no político B ou que estariam satisfeitas com a marca C. A pergunta óbvia é que, se em cada amostra observada um resultado diferente pode ser obtido, como podemos então usar o resultado de uma única amostra observada para saber a opinião de toda a população?
Esse talvez seja o passo lógico mais difícil para compreender, de fato, o que significa o erro amostral. O erro amostral observado de uma única amostra é a diferença entre o resultado daquela amostra observada e o da população alvo, com relação a alguma pergunta específica. Por exemplo, ignorando outros fatores relevantes, uma amostra pode apontar que 35% da população irá votar no candidato A. Se fossemos oniscientes e soubéssemos que na realidade 38% da população votará neste candidato, o erro amostral observado seria de 3%. Outra amostra poderia apontar que 37% da população votará no candidato A; então neste caso o erro amostral observado seria de 1%. Cada amostra terá um erro amostral diferente atrelado a ela (e à intenção de voto). O grande problema é que, na prática, não sabemos de antemão qual o erro amostral observado da amostra específica que foi selecionada, porque não sabemos o resultado para a população toda. Se soubessemos essa quantidade, não seria necessário realizar a pesquisa. No caso das pesquisas eleitorais, se eu já soubesse que 38% da população votaria no candidato A, não haveria porque fazer a pesquisa.
A grande vantagem da amostragem probabilística é que existe um teorema matemático2 que nos diz qual seria o comportamento de infinitas amostras selecionadas usando esse tipo de amostragem. Por exemplo, sabemos que em 50% das possíveis amostras o valor observado da pergunta de interesse será menor do que o valor real da população. Também é possível saber em qual percentual das amostras o erro amostral observado será menor do que 1% (ou 2% ou 10%). Porém, a afirmação mais comum no contexto de pesquisas de opinião pública, é dizer que em 95% das possíveis amostras o erro amostral observado será no máximo d%. Este d depende das probabilidades de cada pessoa ser selecionada e é conhecido como margem de erro. A quantidade de vezes que essa diferença máxima ocorreria, no exemplo 95%, é denominada de nível de confiança ou confiança. Nesse post iremos assumir que a confiança sempre será fixada em 95%.
Note que no parágrafo anterior eu não falo o que ocorrerá com uma amostra específica, mas sim o que ocorrerá com um percentual de todas as possíveis amostras. É um exercício intelectual, teórico; é impossível de ser colocado em prática por diversos razões. As pessoas se recusariam a responder tantas vezes o mesmo questionário, o custo seria infinito, o tempo para completar as infinitas pesquisas também seria infinito, além de diversos outros motivos que claramente inviabilizariam tal procedimento. Qual é então a utilidade de imaginar o que ocorreria se fosse possível selecionar infinitas amostras? O objetivo é entender quanto podem variar os resultados de uma pesquisa de opinião pública por causa das diferentes amostras possíveis. Se o erro amostral observado para a grande maioria das amostras é pequeno, é um indicativo de que podemos ter mais confiança nos resultados de uma amostra específica utilizando esse tipo de amostragem.
Assim, para utilizar os resultados de uma amostra específica para falar de toda a população é necessário incluir a margem de erro na declaração, dessa forma levando em conta a variação esperada do erro amostral observado para todas as possíveis amostras. Neste contexto, se na amostra observada 35% das pessoas entrevistadas declararam que votariam no político B, podemos falar sobre toda a população se adicionarmos a essa afirmação a margem de erro (d), afirmando então que \(35\% \pm d\%\) das pessoas declararam que votarão no político B, com confiança de 95%.
Lamentavelmente a teoria discutida até agora não garante que o erro amostral observado em uma amostra específica esteja de fato dentro da margem de erro. Para entender melhor, considere o seguinte exemplo. Uma fábrica produz canetas, das quais 5% são defeituosas, não escrevem. Imagine que o “João” foi numa loja comprar uma única caneta dessa marca. No ato da compra, ele tem uma probabilidade de 95% de comprar uma caneta que funciona. Depois que ele escolheu uma caneta da prateleira, comprou-a, levou-a pra casa e tentou escrever com ela, não existe mais probabilidade associada à caneta. Ou ela funciona, ou ela não funciona. Ou seja, depois de selecionada uma caneta específica, não importa mais qual era a probabilidade de uma caneta qualquer ser defeituosa, pois aquela caneta (sua amostra) é ou não é defeituosa. Da mesma forma, cada possível amostra têm o erro amostral observado maior (erro) ou menor (acerto) do que a margem de erro. Porém, diferentemente do caso da caneta, não é possível saber se aquela amostra específica acertou ou não o resultado. Por isso, em pesquisas eleitorais, continuamos utilizando a margem de erro, que é uma medida obtida antes da seleção da amostra específica, mesmo depois que a amostra foi de fato observada. É como se o João levasse a caneta pra casa, mas não pudesse tentar escrever com ela. Enquanto ele não conseque testá-la, ela é tratada como se tivesse 95% de chance de funcionar.
É importante entender que o erro amostral, ao menos em teoria, pode ser quantificado. Porém, o que a maioria das pessoas não percebe é que o erro amostral descrito anteriormente apenas considera o erro que ocorre porque selecionamos uma amostra utilizando uma tipo específico de amostragem. Todos os outros tipos de erro discutidos anteriormente são totalmente ignorados nessa conta, e existe muita evidência empírica de que esses outros erros podem ser maiores e mais relevantes do que o erro amostral. Entretanto, geralmente são muito difíceis de serem quantificados de maneira sistemática.
Além disso, essas diferentes fontes de erro se confundem. Nem se soubessemos exatamente o percentual da população que iria votar no candidato A nas eleições, seria possível saber exatamento quanto foi o erro amostral cometido por uma pesquisa específica. Por exemplo, se uma pesquisa aponta que 35% da população vai votar no candidato A, mas sabemos que na realidade 38% da população votará naquele candidato, ainda não é possível afirmar que a diferença observada de 3% ocorreu apenas por causa do erro amostral. Esta diferença pode ter também ocorrido por causa de alguma(s) das outras fontes de erro. Pode ser, por exemplo, que o erro amostral observado foi na realidade de 2%, com o outro 1% de diferença ocorrendo por causa de falhas na cobertura da amostra porque o modo de entrevista utilizado deixou de fora uma parcela da população alvo que proporcionalmente votou mais no candidato A.
A importância da estratificação (geográfica)
Quando existem estratos (subgrupos) identificáveis na população alvo antes de realizar a pesquisa, usualmente existe uma ganho de eficiência ao se utilizar amostragem estratificada. A amostragem estratificada pré-determina a quantidade de entrevistas que serão realizadas em cada estrato. Quanto mais diferente for a opinião (por exemplo, voto no candidato A) em cada estrato, mais efetiva se torna a amostragem estratificada.
Num pais com a dimensão do Brasil, com todas as suas diferenças sócio-econômicas e particularidades regionais, usualmente existe um ganho significativo de eficiência ao se utilizar algum tipo de estratificação geográfica na seleção da amostra. Estratos como regiões e estados, ou até resoluções mais refinadas como Macroregiões ou Microregiões, podem ser utilizados se o escopo do projeto e o tamanho da amostra permitirem. Por exemplo, no contexto eleitoral brasileiro recente, sabemos que a popularidade do Partido dos Trabalhadores (PT) é maior na região Nordeste do que nas outras regiões. Se uma pesquisa nacional fosse realizada sem uma estratificação por região, é possível que a amostra selecionada tenha mais (ou menos) entrevistas proporcionalmente nessa região do que a proporção real de eleitores. Se tiver menos entrevistas, é possível que esta amostra específica apresente um erro amostral observado desfavorável ao PT, e se tiver mais entrevistas, um erro favorável ao PT. Se a amostra for estratificada por região, essa fonte de erros é eliminada. Ainda poderão haver distorções causadas por configurações diferentes de cada possível amostra, mas eliminamos o desbalanço geográfico como fonte de erro amostral. Ou seja, o erro amostral médio cometido em todas as possíveis amostras com a estratificação geográfica será menor do que o daquelas sem estratificação.
O escopo de uma pesquisa afeta bastante a escolha de qual controle geográfico se faz necessário, ou se é possível. Em pesquisas de nível nacional, é muito importante controlar pelo menos por região. Se o número de entrevistas (tamanho da amostra) for grande o suficiente, é possível controlar também pelo estado, e até talvez por alguma área dentro do estado. Menos provavel é a possibilidade de controlar por áreas dentro de cidades selecionadas para pertencer à amostra, pois poucas cidades têm mais do que uma dezena de entrevistas alocadas a elas. Em pesquisas estaduais, é geralmente possível algum controle de regiões dentro do estado (macro/micro regiões), e talvez dentro de alguns municípios em que existe algum interesse analítico, frequentemente nas capitais. Em pesquisas municipais, os controles geográficos são muito importantes, tanto por questões analíticas quanto por eficiência da amostra, porém dependem muito da existência de informações suficientes para que esse controle seja realizado.
Essa questão de controle geográfico varia com o modo, ou metodologia, adotada para a pesquisa. Como foi discutido anteriormente, são três os modos adotados no Brasil (entrevistas pessoais, telefônicas e online). Cada uma delas se baseia em formas muito diferentes de contato com a população em função do meio de comunição envolvido. Para as pessoais, é necessário que o entrevistador se encontre fisicamente com o respondente, enquanto para as telefônicas é preciso que o respondente tenha um telefone (fixo ou celular), para que seja entrevistado. Já a pesquisa online depende do acesso do respondente à internet. Por causa dessa dependência diferenciada nos meios de comunicação, o modo de entrevista acaba determinando as possíveis escolhas de estratos geográficos, assim determinando os desenhos amostrais que podem ser utilizados na pesquisa e influenciando diretamente no erro amostral esperado.
Para pesquisa pessoais é possível ter um controle geográfico muito refinado. Nas pesquisas em pontos de fluxo, o controle geralmente estará limitado ao nível do município. Porém em pesquisas domiciliares, onde o entrevistador encontra os respondentes nas suas casas, é possível ter um controle geográfico mais fino, não só no sentido da estratificação geográfica, mas também no que se refere à seleção de respondentes. Nesse tipo de pesquisa, a seleção da amostra é usualmente feita em estágios, sorteando-se primeiramente municípios, depois setores censitários e finalmente dos domicílios e de seus moradores.
O setor censitário, que é a menor unidade geográfica para a qual existem informações oficiais do Instituto Brasileiro de Geografia e Estatistica (IBGE), possui em média 300 domicílios em áreas urbanas. Assim é possível distribuir uma amostra para pesquisas pessoais domiciliares com enorme controle sobre a dispersão geográfica. Na figura abaixo, mostro o setor censitário onde a minha residência está localizada.
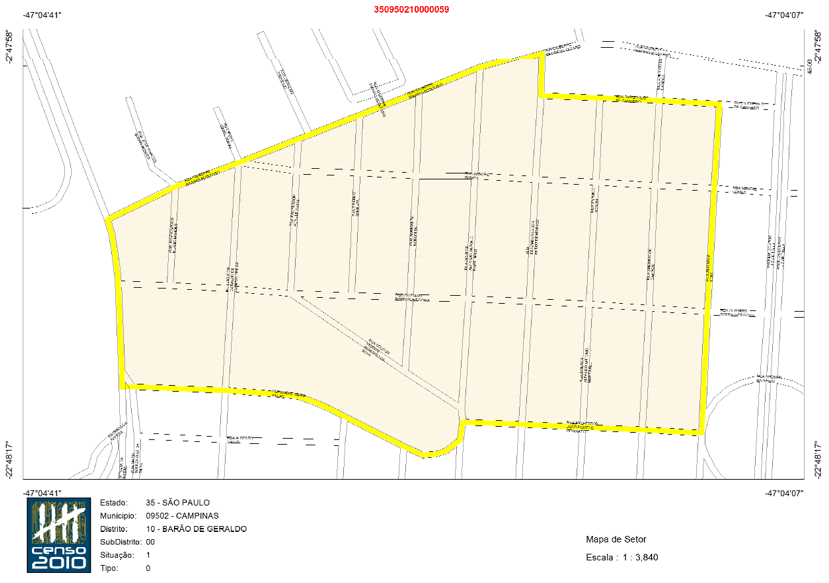
Exemplo de um setor censitário
Nesse link é possível visualizar toda a malha censitária do país, que é composta por mais de 300 mil setores. Na figura abaixo, mostro a malha de setores da cidade de Campinas, onde cada setor está delimitado em azul escuro. Em pesquisas domiciliares, a estratificação geográfica pode ser feita em todos os níveis. No nível municipal, entretanto, ela depende da disponibilidade de informações da malha de setores cenistários. Sempre é possível criar regiões geográficas para estratificação agrupando setores, porém para que essas regiões tenham interesse analítico, devem estar relacionadas com áreas geo-políticas existentes na cidade.
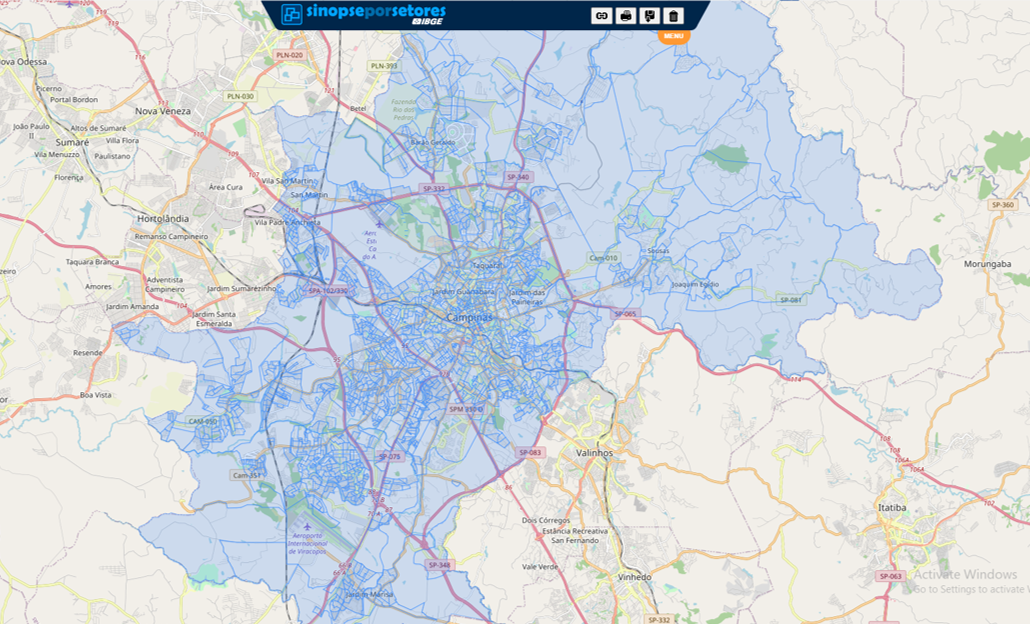
Malha de setores censitários de Campinas(SP)
Apesar da possibilidade de controle geográfico extremamente refinado das pesquisas domiciliares, essa metodologia possue um aspecto negativo, conhecido como efeito de conglomeração. Esse é um termo estatístico relacionado à perda de efetividade do desenho amostral que ocorre por causa da concentração de entrevistas num mesmo local. Esse efeito é quase sempre negativo em populações humanas, porque pessoas que moram próximas umas as outras são mais parecidas entre si do que pessoas que moram longe uma das outras, e isso faz com que haja perda de informação ao selecionar pessoas que residem no mesmo setor. Esse efeito ocorre por uma questão de logística. Para que os entrevistadores não gastem a maioria do seu tempo se locomovendo a domicílios espalhados por toda a cidade, seleciona-se um setor censitário para concetrar as entrevistas. Assim os entrevistadores podem utilizar o seu tempo tentando efetivamente entrevistar as pessoas, sem perder tempo na locomoção. Apesar de haverem muitos ganhos nesse tipo de pesquisa no que se refere à estratificação geográfica, uma parte desta eficiência é perdida por questões logísticas.
Para pesquisas telefônicas também existem dois tipos principais de metodologias: uma de RDD (Random Digit Dialing), onde o cadastro utilizado para selecionar uma amostra tem todos os números de telefone que existem no país, e a outra de Listagem, onde o cadastro é proveniente da listagem dos telefones comprados de algum(ns) fornecedor(es). A diferença entre esses dois tipos de pesquisas telefônicas pode parece sutil, porém é de bastante importância, tanto com relação à qualidade da pesquisa quanto com relação ao tempo de coleta dos dados.
No caso da RDD, utiliza-se cadastros da Agência Nacional de Telecomunicações (ANATEL), onde todos os números de telefones que já foram alocados para alguma operadora telefônica são listados. No cadastro de telefones fixos, é possível identificar o município ao qual o número pertence, mas no cadastro de telefones móveis, não existe nenhuma identificação geográfica. A grande vantagem desse tipo de pesquisa é que a cobertura do cadastro é de 100%, ou seja, todas as pessoas do país que têm telefones têm que estar no cadastro. A desvantagem é que existem muitos números que, apesar de terem sido alocados a operadoras, não estão em uso. Por este motivo, durante a coleta dos dados é comum que muitos telefones sendo contactados não existam, algo que reduz a velocidade execução da pesquisa. Muitas vezes é necessário utilizar um discador automático para que seja possível completar a pesquisa em tempo hábil. A discagem manual de cada número que não existe implica na perda de vários segundos, enquando a utilização da discagem automática leva à perda de muito menos tempo. Outra dificuldade da RDD ocorre no caso de pesquisas municipais. Como não é possível saber à qual cidade um telefone celular do cadastro de da ANATEL pertence (apenas conhecemos o DDD), é necessário fazer um filtro de município no questionário da pesquisa, algo que dificulta a coleta de dados, além de aumentar o tempo necessário para completar a pesquisa.
No caso das Listagens, utilizam-se cadastros comprados de fornecedores. A grande vantagem dessa abordagem é que a proporção de números telefones inativos deve ser bem menor do que no caso do RDD, e também existe a possibilidade de haver informações geográficas para telefones celulares. A desvantagem é que não é possível saber a cobertura dessas listagens, nem também o quão atuais elas são. Mesmo que tenham informações geográficas, estas podem estar desatualizadas. Provavelmente a coleta dos dados com esse tipo de pesquisa será mais rápida, porém a eficiência da amostragem pode ser comprometida por causa da cobertura.
Com relação à estratificação geográfica em pesquisas telefônicas, ela é sempre possível até o nível do DDD, que é um nível geográfico com refinamento maior do que o nível do estado, como pode ser visto no gráfico abaixo. Desta forma, tanto pesquisas nacionais quanto estaduais podem ter uma estratificação geográfica bastante razoável. Porém, em pesquisas municipais, a estratificação será dependente da qualidade da listagem, e não é possível no caso das pesquisas RDD com telefones celulares. Nesse último caso, pode-se perguntar no questionário sobre bairro ou CEP da residÊncia do respondente, e usar estas informações durante a etapa de análise dos dados para ajustar a distribuição geográfica da pesquisa, como será discutido posteriormente. Porém, muitas pessoas desconhecem o seu CEP, e a definição de bairro não é uma informação muito confiável para ser utilizada com o objetivo de melhorar a qualidade da pesquisa.
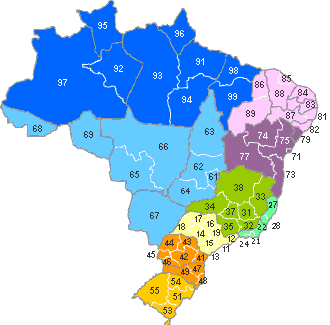
Mapa de DDD’s
Em pesquisas online, as informações disponíveis sobre os respondentes dependem muito da forma de recrutamento utilizada, tema que será discutido na próxima seção (sobre cobertura). Quando existe alguma informação previamente disponível para ser usada na estratificação da amostra, como Estado, Cidade ou CEP, ela pode ser utilizada. Porém, geralmente, não existem respondentes suficientes em várias estratos de interesse, inviabilizando o controle geográfico em níveis mais refinados que estados, ou muitas vezes regiões.
Durante a coleta dos dados por pesquisas online, informações geográficas também podem ser coletadas, como CEP ou então o endereço de IP, ambas informações que permitiriam ajustes geográficos na etapa de análise dos dados da pesquisa, como será discutido posteriormente. Porém, no caso dessas pesquisas online, muitas vezes os respondentes têm preocupação com a sua privacidade e podem não responder ou não permitir o acesso a essas informações.
b2) Cobertura: as dificuldades de acesso às pessoas
A cobertura de uma pesquisa se refere ao percentual da população alvo que pode ser entrevistada. Utilizando os termos da seção anterior, consiste na determinção de quantas pessoas têm uma probabilidade positiva de serem selecionadas para fazer parte da pesquisa. Uma cobertura de 100%, por exemplo, implica que todas as pessoas da população podem ser selecionadas para participar da pesquisa. Uma cobertura de 90% implica que 10% da população alvo têm probabilidade zero de ser selecionado para participar. Quando existe uma parcela da população que não têm chance de participar da pesquisa, a pesquisa potencialmente terá viés de cobertura. O tamanho desse viés depende do percentual de pessoas que não podem ser selecionadas e também do quão diferentes essas pessoas são daquelas pessoas que podem ser selecionadas. Se a proporção de pessoas excluídas é baixa, e/ou se quem é excluído é muito semelhante às que não são excluídas, esse viés pode ser ignorável.
Como foi discutido anteriormente, existem três modos principais de entrevistas utilizados no Brasil, os quais são dependentes de maneiras diferentes dos meios de comunicação. Para entender melhor os pontos fracos e fortes de cada metodologia, é importante também entender quais pessoas não podem ser acessadas/encontradas pelas diferentes estratégias de recrutamento de respondentes, ou seja, entender como o modo de entrevista pode influenciar a cobertura da pesquisa.
Note que quando falamos dos diferentes modos de pesquisa, é comum utilizar o termo recrutamento ao invês de seleção. Algumas vezes não é tão óbvia a diferença entre os dois termos, sendo até utilizados como sinônimos, porém a diferença entre os termos pode ser muito importante para determinar a qualidade de uma pesquisa. Quando o termo seleção é utilizado, implicitamente refere-se a um controle mais rígido sobre os respondentes: apenas pessoas que forem selecionadas podem fazer parte da pesquisa. Quando o termo recrutamento é utilizado, usualmente refere-se a encontrar pessoas com o perfil desejado para a pesquisa, muitas vezes até oferencendo incentivos (financeiros ou não) pela sua participação. O termo recrutamento então está associado principalmente à auto-seleção do respondente: quem decide se irá participar ou não da pesquisa é o próprio respondente. É importante destacar, porém, que independente de haver um seleção rigososa ou não dos respondentes, no final das contas são sempre os indivíduos que decidem se querem participar ou não da pesquisa. A relação entre auto-seleção e não-resposta será discutida na seção seguinte.
Para avaliar o potencial impacto da metodologia (e consequentemente, do modo de entrevista) na cobertura das pesquisas, utilizaremos os dados mais atuais e abrangentes para discutir a dificuldade de acesso dos institutos de pesquisas a sub-grupos da população brasileira. Para esse fim, serão utilizados os microdados da Pesquisa Nacional por Amostragem de Domicílios (PNAD), realizada continuamente pelo IBGE. A PNAD permite a leitura dos resultados em diferentes recortes analíticos e frequência (mensal, trimestral e anual), sendo assim uma das pesquisas mais importantes executadas pelo IBGE (acesse esse link para uma explicação detalhada da pesquisa). Talvez a maior restrição da PNAD seja o baixo nível de refinamento geográfico dos resultados, mostrado na figura abaixo (1A), se limitando às Capitais de cada estado, às Regiões Metropolitanas (RM)(ou Regiões Integradas de Desenvolvimento (RIDE) que contém alguma capital estadual) e o resto do estado.
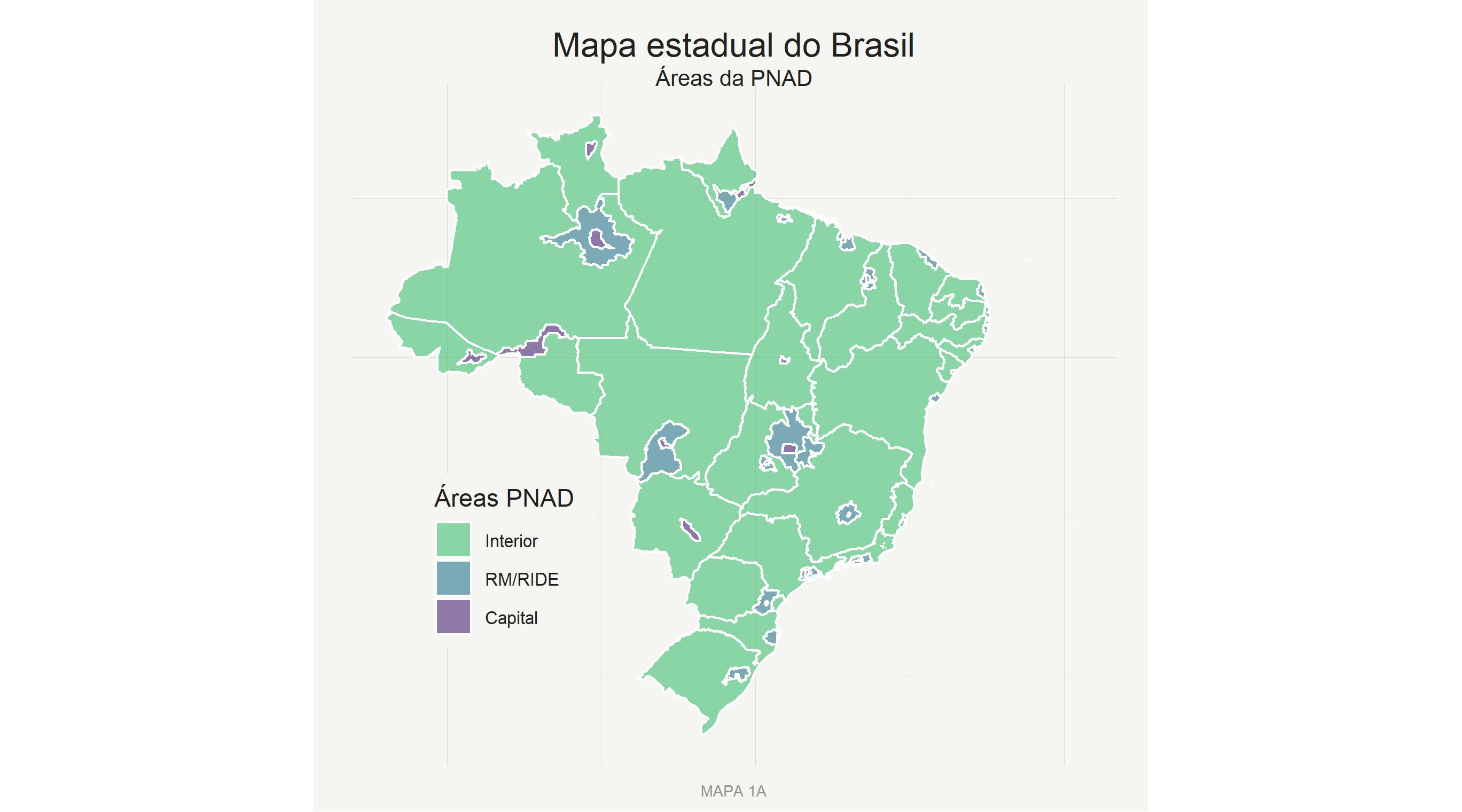
Áreas analíticas da PNADc
Um dos recortes da PNAD versa sobre as características dos domicílios brasileiros, incluindo informações sobre posse de telefone e acesso à internet dos residentes. Também existem informações sobre o tipo do domicílio (se é um apartamento ou não) e sobre a infra-estrutura do mesmo. Alguns dessas informações são relevantes quando consideramos o acesso de entrevistadores à população, o qual é um dos aspectos mais importantes para determinar a cobertura da pesquisa, e consequentemente, o quão bem a metodologia da pesquisa permite avaliarmos a opinião do brasileiro.
A logística da coleta de dados em pesquisas pessoais domiciliares exige que o entrevistador tenha contato com o respondente em sua residência. Pesquisas desse tipo envolvem o deslocamento de uma equipe de entrevistadores (e supervisores), usualmente partindo dos grandes centros urbanos onde se localizam as empresas que realizam a coleta de dados, para o interior, de forma a permitir que pessoas residentes em todo o território brasileiro sejam entrevistadas. Os roteiros de viagem seguidos por essas equipes dependem do número de equipes localizadas em uma àrea e das cidades dessa área onde é necessário realizar entrevistas. Geralmente, a amostra de pessoas/cidades nas várias áreas é restrita a roteiros logisticamente aceitáveis, permitindo que os entrevistadores de uma equipe trabalhem dias completos em numa cidade, depois se locomovendo o mais rapidamente possível para a próxima cidadem do roteiro, de preferência sem “perder” nenhum dia apenas em deslocamento (sem realizar entrevistas).
Nesse modo de entrevista, dois aspectos são importantes para que o entrevistador consiga entrevistar a pessoa selecionada para participar da pesquisa: conseguir chegar ao município de residência, e obter permissão para falar com residentes que moram em lugares com acesso restrito. Pelo primeiro motivo, é comum algumas pesquisas excluírem lugares muito distantes de centros urbanos, geralmente rurais e sem acesso rodoviário. Um exemplo típico de áreas evitadas são os municípios que têm apenas acesso hidroviário no Norte do país. Esses locais são evitados pois representam poucas pessoas no país e o custo de realizar as entrevistas seria alto. O segundo motivo, relacionado ao acesso ao domicílio em si, ocorre pela existência de porteiros. No caso de apartamentos e condomínios, geralmente o acesso às áreas internas só é permitido com autorização de algum residente, dificultando bastante que pessoas residentes nesses locais participem de pesquisas, principalmente quando o procedimento de seleção do domícilio é realizado pelo próprio entrevistador. No caso de favelas, situações similares ocorrem: muitas vezes só é permitido que residentes do local sejam entrevistados se os entrevistadores obtiverem autorização do chefe da comunidade, ou se algum representante dele estiver presente durante a entrevsita. Esse tipo de controle é mais comum em favelas onde existe crime organizado, ou se o controle da comunidade está sendo disputado por diferentes grupos.
De acordo com a PNADc de 2018 (visita 1), mais de 24,3 milhões de pessoas moram em apartamentos (+/- 12,8% da população). Utilizando os dados da PNAD, não existem informações sobre quantas pessoas residem em condomínios ou aglomerações urbanas sub-normais (favelas), porém de acordo com dados do Censo 2010, cerca de 11,4 milhões de pessoas moram em favelas (+/- 6% da população) e 3,1 milhões de pessoas moram em condomínios ou vilas (+/- 1,6% da população). A combinação dessas três estatísticas mostra que provavelmente 38 milhões de brasileiros moram em áreas que podem ser de difícil acesso para pesquisas domiciliares (+/- 19% da população).
A logística de pesquisas telefônicas é mais fácil. O contato com o respondente é feito pelo telefone, ou seja, apenas é necessário que o respondente tenha acesso a um telefone fixo ou celular ativo. É importante mencionar, entretanto, que pesquisas telefônicas de boa qualidade têm que contemplar tanto telefones fixos quanto celulares; caso contrário, a cobertura da mesma será bastante reduzida. Apesar da inclusão dos dois tipos de telefone complicar um pouco a logística da coleta de dados e a análise dos resultados (como será discutido na seção de análise), o ganho em cobertura compensa o esforço. O principal motivo da importância da inclusão dos tipos de telefones é que pessoas que têm Somente Celular, Somente Fixo e Celular e Fixo são bem diferentes entre si, e a exclusão de algum desses grupos pode aumentar bastante o viés de cobertura desse modo de pesquisa.
De acordo com os dados da PNADc de 2018 (visita 1), mais de 199 milhões de brasileiros residem em domicílios onde existe telefone fixo ou onde pelo menos um morador tenha um telefone celular (+/- 96% da população). Uma ressalva importante a essa estatística é que o telefone celular geralmente é considerado como sendo de uso pessoal. Então o fato de um morador ter um telefone celular não necessariamente implica que os outros moradores do mesmo domicílio são acessíveis pelo celular. Até por esse motivo, as perguntas feitas pela PNAD sobre posse de telefone celular (“Neste domicílio, quantos moradores têm telefone móvel celular para uso pessoal?”) e de telefone fixo (“Este domicílio tem telefone fixo convencional?”) são bastante diferentes.
Em pesquisas online, para que uma pessoa possa participar da pesquisa, é necessário que tenha acesso à internet. Como nesses casos geralmente é o próprio respondente que preenche o questionário (auto-preenchimento), ele pode fazê-lo de qualquer local, como de sua casa, do seu trabalho, de uma lan house, ou até do smartphone. A etapa de recrutamento, que consiste em entrar em contato com os potenciais respondentes dando-lhes o link necessário para responder a pesquisa, pode ser muito importante. É possível que o recrutamento seja feito de uma forma que não dependa da internet, o que permite que mesmo uma pessoa sem acesso à internet na sua casa ou celular possa participar da pesquisa; também é importante que pessoas que utilizam a internet com pouca frequência possam ser selecionadas para participar de uma pesquisa.
A forma mais comum de recrutamento online é feita utilizando painéis online. Nestes painéis pessoas se cadastram para poderem ser contactadas para participar de pesquisas, pois recebem algum incentivo (financeiro ou não) para tanto. Outra forma de recrutamento que vem se tornando mais popular é chamada de river sampling, onde as pessoas são recrutadas enquanto utilizam a internet da forma como normalmente fazem. Esse tipo de recrutamento também tende a oferecer algum tipo de incentivo online, como pontos ou acesso exclusivo aos mais variados produtos e serviços. Outra forma bastante popular de recrutamento é através de listagens de emails. O recrutamento offline também é utilizado, muitas vezes feito no momento em que a pessoa iniciaria o acesso à internet, como em Lan Houses ou wi-fi’s públicos, algumas vezes oferencendo como incentivo pela participação na pesquisa o acesso gratuíto. Também é possível que o recrutamento seja feito pelo telefone (Whatsapp, SMS ou Smartphone), ou quando uma pessoa realizar uma compra numa loja física; em alguns casos mais raros, até pode ser feito pelo correio.
Mesmo com dados de uma pesquisa específica sobre o uso da internet, como por exemplo a TIC Domicílios 2018, é difícil avaliar a abrangência (ou cobertura) de uma pesquisa online, principalmente porque o questionário de uma pesquisa pode ser acessado de locais públicos e por causa das diferentes possibilidades de recrutamento. Me parece evidente, no entanto, que conforme a penetração de smartphones for aumentando no país, mais efetivas as pesquisas online podem se tornar. As pessoas poderiam ser contactadas pelo telefone, e responderiam a pesquisa pelo próprio smartphone, tornando a cobertura similar ao caso das pesquisas telefônicas. Nesse post mostraremos estatísticas da PNAD relacionadas à possibilidade de acesso à internet no domicílio, sem nos preocuparmos com a frequência de acesso. A pergunta que consideramos foi esta: “Algum morador tem acesso à Internet no domicílio por meio de microcomputador, tablet, telefone móvel celular, televisão ou outro equipamento?”. De acordo com a PNADc de 2018 (visita 1), aproximadamente 166 milhões de pessoas têm acesso à internet no seu domicílio (+/- 79,9% da população). É importante mencionar também que como, geralmente, as pesquisas online são de auto-preenchimento, pessoas analfabetas não podem participar dessas pesquisas. Ainda de acordo com a PNADc de 2018 (visita 1), aproximadamente 15 milhões de pessoas têm menos de 1 ano de estudo (+/- 7,2% da população).
Na figura abaixo (1B) mostramos uma comparação das estatísticas relacionadas com o acesso aos respondentes por área da PNAD. Para isso utilizamos um mini gráfico de pizza para cada área, indicando três estatísticas diferentes: Sem Internet, em amarelo, que se refere ao percentual de pessoas que residem em domicílios onde nenhum morador têm acesso a internet, Sem telefone, em cinza escuro, que se refere ao percentual de pessoas que residem em domicílios onde nenhum morador têm acesso a um telefone (fixo ou celular) e Sem acesso físico(apartamento), em azul, que se refere ao percentual de pessoas que residem em domicílios classificados como apartamentos. Também mostramos no gráfico os locais onde existem favelas no país, em rosa.
Note que essas estatísticas não têm que somar 100%, o que pode gerar críticas ao uso do gráfico de pizza, porém esta foi a forma encontrada de apresentar, ao mesmo tempo, os aspectos relevantes do acesso aos respondentes para os diferentes modos de pesquisa nas áreas da PNAD. É importante lembrar que o mapa não mostra o tamanho populacional das áreas3, porém sabidamente as maiores concentrações populacionais estão na região sudeste e nos grandes aglomerados urbanos, os quais correspondem aproximadamente aos locais onde existem favelas. O leitor pode olhar cada área com detalhe, se assim desejar, porém o que é importante perceber desse mapa é como o acesso à população têm uma geografia muito diferente para cada modo de entrevista. A existência de porteiros (favelas e apartamentos) é maior em todos os grandes centros urbanos; a maioria dos locais onde pessoas não têm acesso ao telefone estão concentradas no interior das regiões Norte e Nordeste, e finalmente, domicílios sem acesso à internet estão espalhados por todo o país.
É importante fazer algumas ressalvas ao analisar esses dados. Não são todos os apartamentos e favelas que possuem “porteiros”; a posse de telefone celular por um residente não implica que todos os residentes podem ser contactados por celular; e um domicílio ter a possibilidade de acesso à internet não quer dizer que ela é de fato acessada. Porém, a visualização dessas estatísticas deve ajudar o leitor a compreender a complexidade da realização de pesquisas de opinião pública no país, tanto no aspecto da logística quanto dos potenciais erros de cobertura que estarão presentes nos diferentes modos de entrevista.
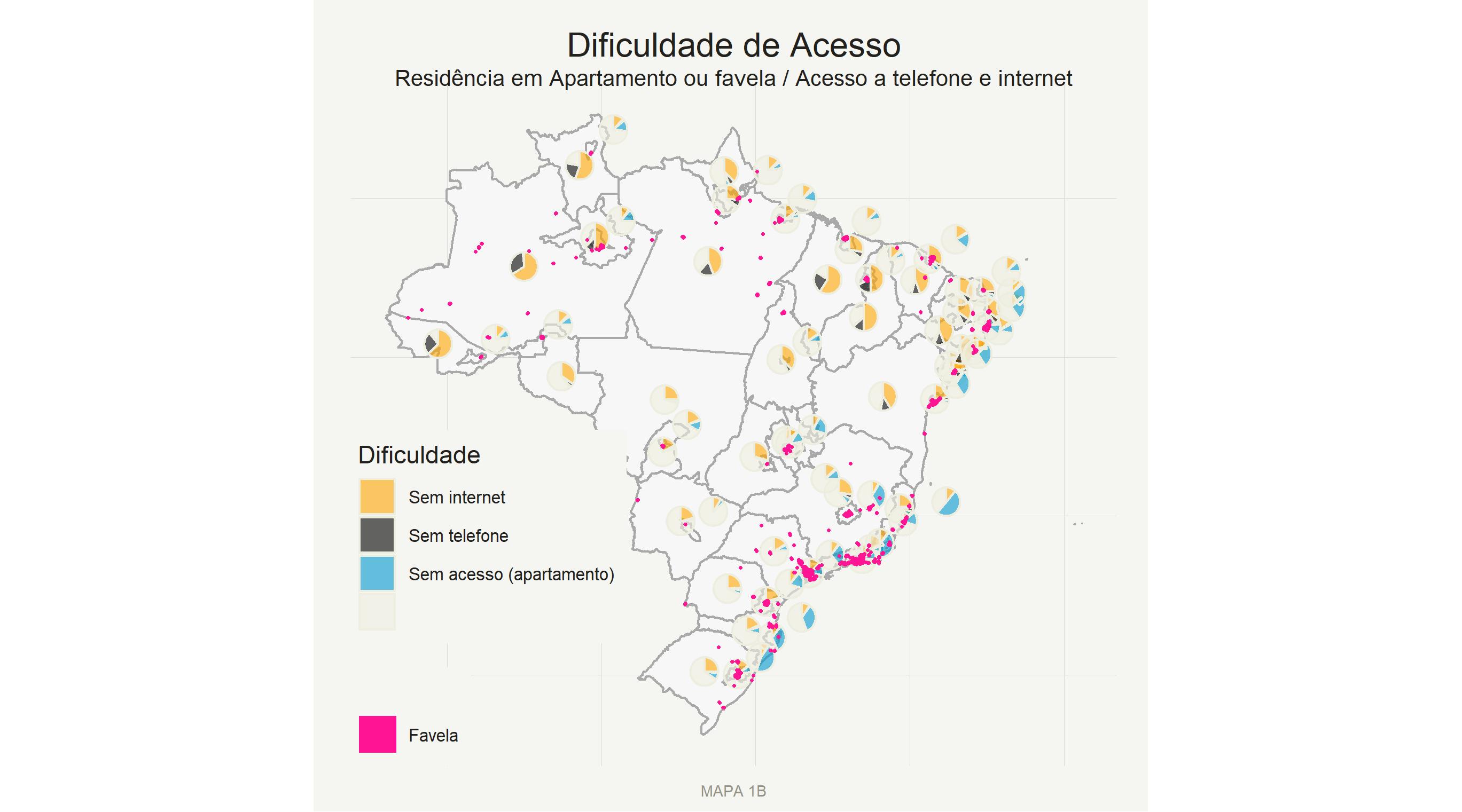
Dados PNADc 2018
b3) Não-resposta: a dificuldade de entrevistar as pessoas
A falta de resposta está ligada principalmente a aspectos práticos, de conseguir contato e a colaboração dos respondetes. O erro de não-resposta provavelmente é o erro mais complexo de ser compreendido e corrigido das pesquisas de opinião-pública. E pode impactar os resultados da pesquisa de maneiras imprevisíveis. Embora exista a não-resposta por item, aqui estamos preocupados apenas com o erro de não-reposta da unidade, ou seja, o erro que ocorre quando pessoas que foram selecionadas para participar da pesquisa não são entrevistadas. Quando existe uma parcela da amostra selecionada que não participa da pesquisa, a pesquisa potencialmente terá viés de não-resposta. O tamanho desse viés depende do percentual de pessoas selecionadas que não puderam ser entrevistadas e também do quão diferentes essas pessoas são daquelas pessoas que foram entrevistadas. Se a proporção de pessoas que não responderam é baixa, e/ou se quem respondeu é muito semelhante a quem não respondeu, esse viés poderá ser ignorável.
Mede-se o gráu de não-resposta de uma pesquisa com a taxa de resposta. Essa taxa diz qual o percentual de pessoas originalmente selecionadas para participar da pesquisa que de fato foram entrevistadas. A importância da taxa de resposta é enorme porque, em algum sentido, ela mede o quão próximo a amostra observada da pesquisa ficou da amostra originalmente planejada. Se a taxa de resposta for perto de 100%, implica que a amostra planejada conseguiu ser executada. Quanto menor a taxa de resposta, mais distante a amostra de fato observada ficou da amostra planejada. Quanto mais distante, mais importante passa a ser a etapa de ponderação dos dados para corrigir o pontencial viés de não-resposta (como será discutido na seção seguinte).
No Brasil não é comum que pesquisas publicadas na mídia reportem a taxa de resposta, inclusive na legislação vigente sobre a publicação das pesquisas eleitorais, não há menção a essa taxa. Por esse motivo é difícil fazer uma meta-análise das pesquisas para compreender o impacto da não-resposta nas pesquisas ao longo dos anos no país. Nos EUA, entretanto, muitas publicações de pesquisas incluem a taxa de resposta pois ela é vista como um selo de qualidade. Uma meta-análise realizada no país há alguns anos mostra que a taxa de resposta tem caído muito em pesquisas telefônicas: no final da década de 90, a taxá média era em torno de 36%, baixando em 2018 a 6%.
A baixa taxa de resposta (ou a sua redução) nas pesquisas de opinião-pública depende do perfil demográfico da pessoa e do modo de entrevista. Porém, de forma geral, acredita-se que as pessoas hoje em dia têm menos tempo e paciência para responder a pesquisas de opinião pública. Tradicionalmente pessoas com instrução mais alta recusam-se mais a participar de pesquisas, bem como homens e jovens. Especificamente em pesquisa pessoais, pessoas que trabalham fora de casa são particularmente dificeis de serem encontradas, as vezes sendo necessário ao entrevistador retornar em horário não-comercial para conseguir uma entrevista. Em pesquisas telefonicas pode ser mais fácil para uma pessoa se recusar a participar de uma pesquisa do que quando está frente a frente com um entevistador. Pode ser ainda mais fácil ocorrer uma recusa se a pesquisa não for realizada por um entrervistador humano (URA). Em pesquisas online, é difícil definir o conceito de taxa de resposta porque geralmente não existe uma amostra selecionada para ser usada como referencial para o cálculo da taxa. Nessas pesquisas usualmente só se sabe quem participou da pesquisa, sem haver controle de quantos se recusaram a participar. Por esse motivo, as vezes utiliza-se o termo viés de auto-seleção para pesquisas online, em referência ao fato que nesse tipo de pesquisa são voluntários que participam. A preocupação geralmente é com grupos de pessoas que são mais pró-ativas para participar de pesquisas do que o resto da população (seja por interesse no assunto ou por receber algum tipo de incentivo para participar). Algumas vezes esses perfis específicos são denominados de respondentes profissionais.
Por causa dos aspectos específicos de cada modo de entrevista, e também porque as taxas de resposta podem ser utilizadas para comparar diferentes pesquisas, é importante que a mesma seja padronizada, deixando claro quais casos devem ser incluídos no numerador e no denominador da taxa. Como exemplo, se numa pesquisa telefônica liga-se para um número inexistente, esse número é excluído do calculo da taxa de resposta, porém se o número existir mas ninguém atender a ligação, o caso é incluído no cálculo. No linguajar das pesquisas de opinião-pública, o motivo da não completação de uma entrevista é denominado de código de disposição. A padronização da taxa de resposta usualmente é definida usando agrupamentos dos códigos de disposição, como pode ser visto nesse relatório.
Ao longo deste post mencionou-se várias vezes que distorções na amostra original devem ser ajustadas/corrigidas na etapa da análise e ponderação dos dados. Porém, pesquisas de melhor qualidade se preocupam em corrigir essas distorções também durante a coleta dos dados, numa tentativa de reduzir o peso do ajuste feito na etapa de ponderação dos dados, de forma que menos suposições tenham que ser feitas para garantir a qualidade do resultado da pesquisa. A forma como se corrige possíveis distorções durante a coleta de dados é denominada de cotas, e será discutida aqui.
Cotas
Durante a etapa de coleta de dados os entrevistadores podem não conseguir entrevistar as pessoas inicialmente selecionadas para participarem da pesquisa. Por isso, é necessário um critério para substituir tais pessoas, o qual é definido durante o planejamento da pesquisa. Geralmente, o critério envolve um número máximo de tentativas de realizar uma entrevista. Também incluí a determinação dos aspectos do perfil do respondente que devem ser considerados ao substituí-lo. Essas variáveis que controlam a substituição do respondente são denominadas de cotas.
A ideia por traz das cotas é muito semelhante à motivação da estratificação discutida anteriormente: fixa-se o número de entrevistas em cada cota de modo que para todas as possíveis amostras observadas, o número de entrevistas em cada uma se mantenha constante. No entanto, o que difere bastante no caso de cotas é a motivação para a escolha das variáveis a serem controladas. Nesse caso, busca-se variáveis sócio-demográficas que sejam relacionadas com a chance de ocorrência do erro de não-resposta. Uma vez que pessoas que trabalham fora de casa são mais difícieis de serem entrevistadas nos domicílios, por exemplo, devemos controlar a proporção de pessoas desse perfil que participa da pesquisa para evitar que ele seja sub-representado.
A sub-representação pode ocorrer quando variáveis importantes, relacionadas à probabiladade de uma pessoa participar da pesquisa, não são controladas nas cotas. Se não conseguir entrevistar uma pessoa desejada em uma pesquisa domiciliar, será feita uma substituição de acordo com a regra pré-estabelecida. No exemplo acima, se o respondente não entrevistado trabalha fora de casa. e essa variável não está nas cotas, ele pode ser substituido por uma pessoa com o mesmo perfil nas variáveis de cota porém que NÃO trabalha fora de casa.
A regra padrão utilizada para substituir respondentes depende da metodologia da pesquisa. Em quase todos os casos a regra é tentar fazer contato/entrevistar a pessoa um número pré-especificado de vezes (frequentemente 3, porém pesquisas de menor qualidade às vezes limitam as tentativas a apenas uma única vez). As variáveis geralmente utilizadas nas cotas (que são correlaciondas com a chance de uma pessoa responder a pesquisa), estão listadas abaixo, juntamente com a justificativa para a sua inclusão.
- Sexo: No geral, é mais fácil encontrar mulheres em casa, como idosas e donas de casa. Elas também são menos propensas a se recusar a participar de uma pesquisa se comparadas aos homens.
- Idade: No geral, é mais fácil encontrar jovens e idosos em casa. Jovens adultos são mais acessíveis pelo telefone celular do que pelo telefone fixo, e também têm uma presença mais forte na internet se comparados com as outras faixas etárias.
- Escolaridade: No geral, pessoas com escolaridade maior se recusam mais a responder às pesquisas. Além disso, pessoas analfabetas não conseguem acessar à internet.
- Ocupação: No geral, pessoas que trabalham são mais difíceis de serem encontradas em casa do que pessoas que não trabalham. Elas também têm chance maior de ter um telefone celular pessoal, e muitas vezes podem acessar a internet com mais frequência e de outros lugares além da residência, como do trabalho.
- Classe Social: No geral, pessoas de classe social mais alta são mais inacessíveis, pois moram em condomínios fechados ou em apartmentos. Elas também são mais propensas a recusarem participação numa pesquisa. Por outro lado, têm chance maior de possuir um smartphone de uso pessoal e de acessar a internet com frequência.
- Tipo de residência: No geral, pessoas que residem em apartamentos são mais difíceis de serem contactadas do que moradores de casas, com exceção de condomínios fechados ou mansões.
A etapa de coleta de dados se faz mais demorada com a utilização de cotas, entretanto é importante utilizá-las. Por isso é importante ser criterioso na escolha das mesmas, pois não é possível controlar todas as variáveis que podem ser relacionadas com a chance de algúem responder. Além disso, é comum que algumas cotas deixem de ser controladas no final da coleta de dados, pois conforme as cotas mais fáceis de serem preenchidas vão se esgotando, agumas combinações improváveis de perfis difíceis de serem entrevistados sobram para o final da coleta de dados, impossibilitando o termino da pesquisa no prazo desejado. Um exemplo típico desse tipo de combinação que dificulta muito o campo são pessoas com menos de 24 anos e com escolaridade superior completa.
A utilização de cotas na coleta de dados é uma das maiores críticas dos acadêmicos às pesquisas realizadas na prática, por permitir a substituição de pessoas que haviam sido originalmente selecionadas para participar da pesquisa. Não é o objetivo desse post discutir mais profundamente a questão, porém se você, leitor, tiver mais interesse no assunto, é o tema central de toda a discussão sobre amostragem na minha tese de doutorado.
C) Análise das pesquisas de opinião (Ponderação dos dados)
Nas seções anteriores ficou claro que a amostra inicialmente desenhada para a pesquisa não é aquela que é efetivamente observada ao final da coleta de dados. O efeito cumulativo dos erros, denominado de viés metodológico, têm impacto direto na capacidade de entender a população alvo sendo estudada a partir da amostra observada. Essa distorção na amostra incialmente planejada pode ser corrigida durante a análise, porém é necessário fazer suposições sobre os viéses causados pelos erros.
A técnica mais utilizada para este fim é chamada de ponderação (ou pós-estratificação). A ponderação funciona de uma forma relativamente simples, aumentando o peso de grupos de pessoas que foram sub-representados na pesquisa, e complementarmente, reduzindo o peso de grupos super-representados. Por exemplo, se numa pesquisa o percentual de mulheres observado foi de 25%, porém sabe-se que na população alvo as mulheres representam 50% das pessoas, então na pesquisa o peso relativo das mulheres será dobrado para que elas passem a representar o percentual correto da população; ao mesmo tempo, o peso dos homens também será reduzido. Para isso, adiciona-se a base de dados da pesquisa uma variável de peso, que conterá todos os ajustes necessários. Dessa forma, para que os ajustes sejam aplicados aos resultados da pesquisa observada, basta calcular os resultados ponderados por essa variável de peso.
Os pesos podem ser calculados de forma que muitas variáveis sejam ajustadas simultaneamente, permitindo assim que estratégias de correção bastante complexas sejam implementadas. A ponderação é muito utilizada por ser bastante flexivel e de fácil disseminação, pois o ajuste final fica codificado juntamente com o banco de dados da pesquisa. Dessa forma pode ser facilmente utilizada tanto internamente pelo instituto de pesquisa, quanto publicamente por consumidores dos dados da pesquisa.
Existem outras técnicas de análise bastantes relevantes que podem ser utilizadas para ajustar aspectos importantes de pesquisas de opinião, porém não serão discutidas aqui: Multilevel regression with post-stratification, Propensity score mathing, Non-response analysis e Likely voter models.
c1) Quais variáveis devem ser ajustadas na ponderação?
O objetivo da ponderação é corrigir os vieses que podem ocorrer durante a execução da pesquisa. A efetividade dos ajustes depende de quais variáveis são utilizadas, e das suposições que são feitas sobre a importância dessas variáveis para corrigir/remover o viés. Nesses ajustes podem ser utilizadas apenas variáveis que foram incluídas no questionário da própria pesquisa e para as quais os valores populacionais sejam conhecidos, ou seja, estão disponíveis em pesquisas públicas (preferencialmente confiáveis). A melhor estratégia geralmente envolve planejar o ajuste antes da coleta dos dados, pois dessa forma variáveis importantes para a remoção dos potenciais viéses podem ser incluídas no questionário e enunciadas de forma a reproduzir as perguntas feitas nas pesquisas utilizadas como referência para os ajustes.
Por exemplo, como vimos na seção b2 sobre a cobertura das pesquisas, sabemos que pesquisas online, com recrutamento online, têm dificuldade de encontrar respondentes no interior das regiões Norte e Nordeste, fato que muitas vezes faz com que essas regiões sejam sub-representadas nessas pesquisas. Se for adotada a estratégia de aumentar o peso dos respondentes dessas áreas para terem o mesmo tamanho relativo que têm na população brasileira, uma suposição bastante forte está sendo feita: de que as pessoas que não foram entrevistadas são iguais às pessoas que foram entrevistadas. Essa suposição sempre é forte, porém no contexto de pesquisas online é ainda mais forte. Sabe-se que a incidência da internet nessas regiões é baixa e que pessoas que acessam pouco ou quase nunca à internet são diferentes daquelas que acessam a internet com frequência com relação a vários aspectos, como renda, tipo de trabalho e acesso à informação. Ou seja, ao fazer esta suposição ignora-se não somente o tamanho do erro de cobertura, mas também a sua gravidade. O viés de cobertura nesse caso é potencialmente muito grande, e o ajuste sendo aplicado não leva em consideração aspectos importantes da questão.
Nesse exemplo, um ajuste mais razoável (que faz suposições mais fracas), seria também considerar uma outra variável importante: frequência de uso da internet. Uma estimativa confiável dessa informação no nível populacional pode ser obtida de pesquisas como a TIC Domicílios 2018. Se a mesma pergunta for incluída na pesquisa online sendo realizada, ela pode ser utilizada na etapa de ponderação dos dados. Essa estratégia então ajustaria o peso relativo de pessoas que utilizam pouco a internet, as quais provavelmente estão sub-representadas na amostra online. Mais que isso, se o recrutamento foi online, não existirão pessoas na pesquisa que não usam a internet. Porém tais pessoas existem na população geral, fato esse que ficará evidente na ponderação pois não será possível criar um fator de ajuste para essas pessoas na pesquisa. Note que nesse ajuste, suposições continuam sendo feitas, porém são mais fracas.
Outra alternativa nesse caso seria divulgar a pesquisa se referindo a um público alvo mais realista. Ao invês de dizer que a pesquisa representa a população inteira, pode-se dizer que ela representa a população brasileira com acesso à internet. Dessa forma, o viés de cobertura seria, em grande parte, eliminado.
Mesmo no caso idealizado, onde apenas o erro amostral se faz presente nos resultados da pesquisa, a ponderação dos dados seria recomendada. Em primeiro lugar, porque a amostra pode ser desbalanceada intencionalmente, com grupos de pessoas tendo probabilidades de serem selecionadas não-proporcionais ao tamanho relativo dos grupos aos quais pertencem. Nesses casos é necessário ajustar a amostra para corrigir esse desbalanço amostral. Em segundo lugar, para ajustar variáveis sócio-demográficas com distribuição conhecida na população alvo, de forma que distribuição dessas variáveis na amostra observada coincidam com os totais populacionais. Esse ajuste pode ter tanto caráter estético, quanto de fato melhorar a efetividade da pesquisas se as variáveis ajustadas forem correlacionadas com variáveis análiticas importantes, como intenção de voto no caso de pesquisas eleitorais.
As variáveis que devem ser utilizadas dependem do modo de entrevista. No geral, todas as variáveis discutidas na seção sobre as cotas podem ser também consideradas nessa etapa. Em pesquisas domiciliares, por exemplo, informações como tipo de residência e quantos dias por semana a pessoa fica em casa, poderiam ser usadas para tentar corrigir o viés de cobertura e de não-resposta, porém a última pode não ter um referencial público.
Em pesquisas telefônicas atenção especial é dada à questão do tipo do telefone, pois para selecionar a amostra telefônica utilizam-se dois cadastros, um de telefones fixos e um de telefones celulares. A motivação em considerar essa informação na ponderação é porque pessoas que têm os dois tipos de telefone têm mais chance de pertencer à pesquisa e a sua proporção na amostra pode ser super-estimada. Além disso, existem estudos mostrando que tais pessoas têm perfil de voto mais conservador, aumentando o potencial de um viés relevante na pesquisa. Em pesquisas realizadas por URA é importante tentar corrigir o viés que pode ocorrer por subgrupos da população não participarem de pesquisas desse tipo, porém quais ajustes devem ser feitos ainda não é tão claro.
Em pesquisas online atenção especial é dada a informações como frequência de uso da internet, pelos motivos discutidos no início da seção. Um outro aspecto importante com relação às pesquisas online que merece atenção são os respondentes profissionais. Pesquisas onde o recrutamento é feito somente em painéis são muitas vezes criticadas, pois respondentes profissionais se cadastram nesses paíneis com o objetivo de ganhar incentivos para responder a pesquisas. Estes são muito diferentes das outras pessoas, geralmente mais pró-ativos, principalmente em questões relacionadas ao uso da internet e adoção de novas tecnologias. Para tentar remover esse tipo de viés, uma opção é utilizar alguma pergunta sobre o tipo de uso da internet que o respondente faz.
Os tipos de variáveis consideradas também dependem do objetivo da pesquisa. No contexto específico de pesquisas eleitorais, por exemplo, onde o objetivo é prever corretamente a intenção de voto das pessoas, algumas variáveis relevantes que podem ser consideradas são: religião, recebimento de auxílio do bolsa-família, voto na eleição anterior e bairro/CEP. Nesse caso específico, busca-se variáveis que estão relacionadas com o voto e que não sejam muito correlacionadas com as variáveis de cota. Com isso haverá um ganho adicional por também poder controlar essas variáveis na ponderação.
c2) Truncamento dos pesos (Viés versus variância)
Apesar da ponderação ser um técnica de extrema importância para ajustar os resultados de uma pesquisa, é necessário certo cuidado ao utilizá-la. Se muitas variáveis com muitas categorias forem utilizadas, podem haver combinações de algumas categorias de variáveis que tenham um número muito pequeno de entrevistas. Nesses casos, pode não ser possível reproduzir os percentuais populacionais na pesquisa.
Nesse mesmo contexto, uma situação menos extrema mas bastante relevante ocorre quando existem entrevistas suficientes para calcular o ajuste, porém os pesos necessários para corrigir a amostra são muito grandes. O problema com pesos grandes, ou extremos, é que eles fazem com que alguns poucos respondentes tenham uma importância muito grande para o resultado da pesquisa. A consequência desses pesos grandes é que os resultados da pesquisa se tornam instáveis, pouco confiáveis, pois podem variar muito entre possíveis amostras que poderiam ter sido selecionadas da população alvo. Isso quer dizer que se for realizada uma outra pesquisa similar, os resultados que eram de alguma forma baseados nessas pessoas com pesos grandes podem não ser observados novamente. Ou seja, aquilo que parecia ser uma resultado importante era apenas “ruído” amostral. Nesse contexto, utilizar cotas também é importante pois é uma forma de reduzir o tamanho dos pesos necessários após a coleta dos dados.
Nesse exercício mental de imaginar que a seleção de uma amostra pode ser repetida infinitas vezes usando a mesma metodologia, essa variação entre os resultados das possíveis amostras chama-se variância. Quanto maior a variância, mais instáveis são os resultados de uma pesquisa, consequentemente sendo menos confiáveis. A margem de erro, discutida anteriormente, nada mais é do que uma forma de quantificar essa variação dos resultados da pesquisa causada pela seleção de uma amostra especifica da população. O viés, por outro lado, geralmente é definido como sendo um erro “fixo”, que é constante em todas as possíveis amostras . Esse erro não é causado pelo fato de selecionar uma amostra específica, mas por algum outro motivo de algo que ocorreu durante a execução da pesquisa. Por exemplo, em pesquisas eleitorais, se o viés for de 5% é como se todas as possíveis amostras tivessem a intenção de voto do candidato A super-estimadas, sempre 5% maior do que a realidade.
O viés e a variância são igualmente importantes para determinar a precisão de uma pesquisa de opinião pública, e ambos devem ser evitados. No contexto discutido aqui, geralmente deseja-se remover todo o viés dos resultados da pesquisa observada, ou seja, tenta-se ajustar o maior número possível de variáveis. Porém se esta estratégia for repetida em todas as possíveis amostras, apesar do viés ser reduzido, a variância da metodologia aumenta muito, fazendo com que os resultados fiquem, em média, com um erro maior. Muitas vezes a melhor estratégia para a redução do erro médio é permitir a ocorrência de um pouco de viés, pois desta forma a variância será menos inflada.
Com os pesos da ponderação, é geralmente isso que ocorre. Assim, no caso descrito acima onde os pesos do ajuste são muito grandes consequentemente inflando a variância, uma estratégia comum é truncar o pesos, de forma que eles não possam ser maiores do que um valor máximo X. Pesos maiores serão alterados, passando a ter o valor de X. Dessa forma adiciona-se um pouco de viés nos resultados da pesquisa, pois agora o ajuste aplicado na amostra não reproduz exatamente a distribuição populacional dessas variáveis conhecidas. Em compensação, a variância tem seu tamanho reduzido. O balanço entre viés e variância, nesse contexto, é determinado pelo valor X. Em termos práticos, é impossível distinguir o viés da variância se existe apenas uma única pesquisa para analisar, então a decisão sobre qual deve ser o tamanho de X é feita fazendo-se algumas suposições sobre o comportamento dos pesos. Quando existem mais pesquisas para balizar o tamanho de X, suposições mais fracas podem que ser feitas.
Conclusão
Fazer pesquisas de opinião pública para tentar mensurar a opinião coletiva em um país com dimensão continental e com todas as nuances regionais como o Brasil é extremamente difícil. Some-se a isso a dificuldade de entrar em contato com as pessoas, de prender a sua atenção por alguns minutos, de medir corretamente a sua opinião, e de extrapolar os resultados de alguns milhares de pessoas para representar mais de 200 milhões de vozes e temos uma receita muito difícil de ser executada com sucesso.
Não é só que o fenômeno sendo medido é complexo, mas também é muito difícil ser medido! Para que a opinião pública seja mensurada corretamente, é preciso tempo, dinheiro, conhecimento e experiência. É uma tarefa difícil, que exige inúmeros profissionais de diversas áreas, com conhecimento teórico e prático, mas é possível. No caso de pesquisas eleitorais, onde existem mais restrições sobre a quantidade de tempo e dinheiro disponível, decisões têm que ser tomadas ao longo da execução da pesquisa para que ela seja exequível, mesmo que possam reduzir a qualidade da mesma.
Se você, leitor, tem como objetivo produzir pesquisas de opinião, os temas discutidos nesse post podem ajudar a compreender quais aspectos metodológicos são importantes para que você obtenha resultados com a precisão, e com a generalidade, necessárias para que seus objetivos possam ser atingidos, dentro do seu prazo e respeitando o seu orçamento. Se, por outro lado, você consome dados de pesquisas, esse post deve ajudá-lo a compreender quais aspectos metodológicos são importantes para determinar a qualidade das pesquisas, permitindo assim que você possa dar o peso apropriado às informações contidas nelas para formar sua própria opinião.
Todas as pesquisas de opinião NÃO são iguais. Apesar do título grandioso do post, eu não digo quais são as melhores formas de medir a opinião pública no Brasil. Não digo, porque não existe UMA metodologia obviamente melhor, em todos os contextos, mesmo sem considerar tempo e dinheiro. Existem aspectos metodológicos, no entanto, que indicam a preocupação dos executores com a qualidade da pesquisa. Entre estes, talvez o aspecto mais relevante seja a preocupação com erros de não-resposta, tanto durante (controle) quanto depois (ajuste) da coleta dos dados.
Pesquisas de opinião podem ser importantes para formar nossas próprias opiniões, para entender como a população pensa e para decidir políticas públicas, entre dezenas de outras utilidades. Porém é importante compreender que além dos vieses metodológicos que podem existir nas pesquisas, a opinião pública pode também se alterar. Não baseie sua opinião apenas em uma pesquisa, que usa uma única metodologia, que é executada por um único instituto de pesquisa, e é realizada em um único momento do tempo. A melhor forma de conhecer qual é, de fato, a opinião pública, é mensurá-la com metodologias diferentes, em momentos diferentes. Desta forma conseguimos separar erro amostral do viés metodológico, distinguindo ruído de sinal. Como disse Jonathan Swift, um escritor anglo-irlandês, considerado por muitos o principal satirista de prosas da língua inglesa:
“É tolice de muitos confundir o eco de um coffee-house em Londres com a voz do reino.”
A expressão “prever corretamente” está entre aspas pois pode ser interpretada de diferentes maneiras, como acertar a ordem de preferência aos candidatos na eleição, acertar quem ganhará as eleições ou prever dentro das margens de erro os percentuais obtidos por cada candidato, entre outras. Tenho dois vídeos no canal do youtube EstaTiDados, que discutem alguns aspectos importantes para fazer uma avaliação “justa” da performance das pesquisas eleitorais (vídeo 1 e vídeo 2).↩︎
Esse teorema, conhecido como Teorema do Limite Central, é um dos mais famosos da Estatística. Ele é utilizado em muitos contextos diferentes, com algumas formulações específicas para amostragem de populações finitas.↩︎
Em mapas estaduais desenhados com anamorfose geográfica, cada estado é redesenhado de forma que seu polígono sofre uma deformação proporcional à população residente.↩︎