
O impacto das suposições nas previsões relacionadas ao Coronavírus (COVID-19)
By Neale Ahmed El-Dash on Apr 6, 2020
Neste post discutiremos o impacto das suposições feitas pelos cientistas nas previsões relativas ao Coronavírus (COVID-19). Muitas suposições têm que ser feitas para se prever o futuro. Uma das mais importantes parece ser o percentual de pessoas que foram infectadas pelo vírus, mas não foram testadas. Para tentar avaliar o impacto dessa e de outras suposições, apresentaremos um modelo que contempla tanto a questão da sub-notificação quanto a demanda de leitos hospitalares.
Introdução
Estamos vivendo um momento na nossa história de muito medo e insegurança, causada pelo surgimento do Coronavírus (COVID-19) no final do ano passado em Wuhan, na China, e a sua posterior dispersão para o resto do mundo; ganhou o status de pandemia pela Organização Mundial de Saúde (OMS). Nessa trajetória entre a China e o resto do mundo, esta doença deixou, por enquanto, aproximadamente 40 mil mortos. Para os interessados, vale a pena ver essa reportagem do New York Times, que mostra de maneira interativa onde o vírus surgiu e como ele se espalhou.
Por ser um vírus novo, ainda existem muitas incógnitas a respeito do mesmo, inclusive a sua letalidade e a velocidade de transmissão. Apesar disso, foram feitas previsões sobre o número de mortes, e baseado nisso foram adotadas medidas para conter a disseminação do vírus pela grande maioria dos países. Alguns adotaram medidas mais duras, outros mais brandas, e uns agiram mais rápidos que outros para implementar ações de contenção. Nesses links é possível entender as medidas tomadas por vários países, e quando elas foram implementadas: Folha, Politico, Usa Today.
Não existe uma receita clara sobre quais são as medidas mais efetivas, até porque o comportamento do vírus ainda é bastante desconhecido, e a realidade em cada país ou cidade é bastante diferente. A maioria das ações envolve algum tipo de isolamento social (ou quarentena) da população, por períodos de tempo variáveis, em contextos diferentes. O isolamento adotado é geralmente para toda a população (isolamento horizontal), ou apenas para sub-grupos que têm um risco maior de contrair ou de sofrer cosequências mais graves dessa doença (isolamento vertical). A grande maioria dos eventos esportivos foram cancelados e atividades consideradas não-vitais, como ir a shows ou praticar esportes coletivos, bem como também frequentar igrejas e parques, são evitadas ou até proibidas. Escolas foram fechadas. Quem consegue trabalhar a distância (home-office) foi incentivado ou obrigado a fazê-lo, e o resto das pessoas que não consegue exercer sua profissão remotamente tiveram férias compulsórias decretadas, simplesmente não estão trabalhando, ou até foram demitidas. O transporte público foi reduzido, ou até mesmo deixou de funcionar em alguns casos. Apenas funções consideradas essenciais continuam sendo realizadas, como atividades relacionadas a saúde, acesso a alimentos, farmacos e bancos.
Apesar da grande incerteza sobre esse novo vírus, têm sido tomadas medidas fortes no mundo inteiro, cada uma com o seu sabor especial; apesar das diferenças entre elas, não há dúvida de que tais ações afetam drasticamente não só a vida de bilhões de pessoas, como também a capacidade de muitos países de cuidarem dos seus cidadãos. A motivação por trás dessas restrições a nossa liberdade são as previsões científicas sobre o número potencial de mortes a serem causadas pelo vírus em escala global. Essas previsões levam em conta a velocidade com que o vírus se espalha e a disponibilidade de leitos hospitalares com equipamentos especiais para os mais afetados; elas são feitas por especialistas em epidemiologia, com o auxílio de dados coletados sobre o vírus e com a ajuda de modelos matemáticos/estatísticos.
Modelos são a descrição de uma estrutura subjacente que seria capaz de gerar o conjunto de dados sob análise. Esta descrição geralmente é um expressão matemática formal do processo de geração dos dados. Modelos simplificam nossa visão do mundo, e são utilizados porque ajudam na compreensão dos dados. No contexto descrito aqui, esses modelos são utilizados para entender o número detectado de casos e mortes causadas pela doença. A partir dessas informações tentamos prever o comportamento do vírus no futuro e quais pessoas serão infectadas, como também as características das pessoas com maior risco de morte, assim podendo prever a demanda por leitos hospitalares.
Algumas previsões do impacto do vírus no Brasil foram divulgados na mídia. A previsão mais recente do Imperial College estima que ocorreriam \(1.102.439\) mortes causadas diretamente pelo Coronavírus se medidas de distanciamento social não fossem implementadas. Já o biólogo Atila Iamarino, que tem recebido bastante atenção nas redes sociais, divulgou um vídeo onde prevê a morte de 1.4 milhões de brasileiros se o governo não tomasse medidas preventivas. Também afirma que ocorreriam mais 1.4 milhões de mortes causadas indiretamente pelo vírus por causa da falta de leitos hospitalares.
Eu trabalho com modelos ao longo de toda a minha carreira profissional, como também trabalham quase todos os estatísticos e matemáticos. Tais modelos são fundamentais para tentarmos simplificar e compreender o mundo em que vivemos, e são mais importantes ainda se o objetivo é prever o futuro. Acredito que agora, nesse momento em que vivemos, estejamos presenciando o maior impacto de um modelo na nossa sociedade em todos os tempos, e em uma escala global. Nunca antes na história da humanidade se colocou tanta responsabilidade em um modelo1. Porém, junto com o orgulho de ver uma ferramenta tão importante para mim ser colocada numa posição de tanto destaque mundialmente, também tenho muita preocupação. Apesar de modelos serem absolutamente essenciais para prever o futuro, sei que também são a culminação de dezenas de suposições, feitas sobre os mais diversos aspectos do tema sendo estudado (nesse caso específico, do comportamento do novo vírus).
Antes de continuar a discussão, vou definir o significado de suposição, pois esse termo será fundamental em toda a discussão que será apresentada neste post. De acordo com o site dicio.com.br, uma suposição é:
“Ponto de vista formado sem comprovação; hipótese, conjectura. Opinião que se forma sem provas sobre o assunto em questão: seu argumento foi só uma suposição.”
Fazer uma suposição não é algo ruim; faz parte do método científico. A ciência consiste, em grande parte, em estudar cada suposição (ou hipótese) para avaliar a sua veracidade. As que são verdadeiras são incorporadas ao nosso conhecimento; as que são refutadas são substituidas por outras, mais refinadas ou específicas, que também terão que ser avaliadas futuramente. Como a ciência está em constante progresso em qualquer momento do tempo e em relação a qualquer assunto sendo estudado, sempre existirão muitas suposições sendo feitas. Se não houvessem mais suposições, não haveria mais o que estudar.
Não é diferente com relação ao estudo do Coronavírus. Não estou afirmando que tudo que se sabe sobre o vírus são suposições, muito pelo contrário. Existem séculos de conhecimento acumulado estudando epidemias e vírus que estão sendo utilizados nas previsões publicadas. Porém a forma como modelamos esse vírus, como representamos algumas das características que diferenciam esta epidemia e este vírus dos outros, são suposições. Também fazemos suposições importantes sobre o impacto das medidas de distanciamento social e da demanda de leitos hospitalares.
Estas suposições são feitas não somente porque o vírus é novo, mas também por falta de informação. Não sabemos, por exemplo, quantas pessoas de fato foram já infectadas pelos vírus. Temos informações somente sobre aquelas pessoas que foram testadas; conhecemos apenas o número mínimo de infecções que ocorreram. Entretanto, sabemos que na realidade a incidência do vírus deve ser maior, porém não sabemos quão maior. E mais importante que isso: uma vez que é mais provável que somente pessoas com sintomas mais graves ssejam testadas (como pode ser visto nessa notícia), se torna óbvio que enfrentamos um viés de seleção potencialmente grande, com o poder de distorcer significativamente as estatísticas sobre o vírus. Como podemos avaliar o impacto dessa sub-notificação não-ignorável da incidência da doença nas previsões que estão sendo divulgadas?
Nesse post eu utilizo um modelo epidemiológico que prevê o número de infecções, internações hospitalares e mortes causadas pelo vírus, porém modificado para também poder levar em conta a taxa de sub-notificação do número de infecções com o Coronavírus. Meu objetivo é avaliar diferentes cenários (ou suposições) de sub-notificação e prever o impacto nas previsões de mortes e da necessidade de leitos hospitalares. Este mesmo modelo, em combinação com os cenários, também permite avaliar por quanto tempo será necessário ficarmos em quarentena.
Uma variação do modelo epidemiológico SEIR
O modelo epidemiológico que eu vou utilizar nesse post faz parte de uma classe de modelos chamada de modelos compartimentados. Esses modelos simplificam a comprensão da dinâmica de doenças infecciosas, dividindo a população em grupos (compartimentos exclusivos), e supondo que todas as pessoas dentro de um mesmo grupo são iguais. Esses modelos são determinísticos. Existem versões estocásticas, que podem ser bem mais realistas, porém bem mais complexas e demoradas para analisar. Os modelos determinísticos são geralmente suficientes para prever o comportamento médio da população, sendo úteis para entender como uma doença se espalha e fazer previsões do total de pessoas que serão infectadas ou a duração total de uma epidemia. Também ajudam a compreender como uma epidemia pode se comportar sob diferentes suposições.
Talvez a maior suposição sendo feita por esse modelo determinístico seja que a densidade populacional não é levada em conta; pressupõe que todos da população podem fazer contato uns com os outros, independentemente do tipo de moradia, do local de residência ou trabalho e de hábitos sociais. Essas simplificações sobre o nosso modo de vida são extremamente fortes no que diz respeito a características importantes que impactam na velocidade de disseminação do vírus. Elas também sugerem que o vírus se espalha de forma mais fácil do que na realidade. Ou seja, ao utilizar esse modelo determinístico estamos supondo um cenário provavelmente pior do que a realidade.
Nesse post usaremos uma variação de um modelo conhecido como SEIR, o qual recebe esse nome porque supõe (modela) a população como sendo dividida em 4 grupos, os quais são representados pelas letras que compõem o nome:
- suscetíveis (S): São pessoas da população sendo estudada que ainda não foram expostos, no caso ao vírus, mas são suscetíveis a contrair a doença.
- expostos (E): São pessoas que ja foram expostas ao vírus e estão infectadas, embora não sejam infecciosas (e ainda não apresentem sintomas), ou seja, não podem contaminar outras pessoas.
- infectados (I): São pessoas que não somente foram infectadas, mas são infeciosas; apresentam sintomas. Essas pessoas podem contaminar pessoas do grupo dos suscetíveis se tiverem contato com eles.
- removidos (R): São pessoas que foram removidas da população sob estudo. Não têm mais a doença (porque ou se recuperaram ou estão mortas) e não podem ser infectadas novamente.
Nesse modelo é possível especificar o tempo médio de transição de um grupo para o outro, além de também controlar como esses grupos interagem. Para todos esses grupos, definem-se taxas de entrada e saída, que são utilizadas para controlar a velocidade com que os indivíduos passam de um grupo para outro. Uma vez que os grupos (estágios da doença) são conectados em ordem (S -> E -> I -> R), a taxa de saída do grupo anterior é também a taxa de chegada no novo grupo. No caso dos suscetíveis (S), não existe taxa de entrada porque estamos supondo que ninguém pode ser infectado com a doença novamente. A saída desse grupo implica que uma pessoa pegou a doença. A taxa de saída é controlada pela quantidade de contatos que pessoas infectadas têm com as suscetíveis, como também a velocidade da disseminação do vírus. Essa é a mesma taxa que define a entrada de novas pessoas no grupo dos expostos (E); já contraíram a doença, mas ainda não são infecciosos. O tempo no grupo se refere ao tempo de incubação da doença, e a saída refere-se a transição para o grupo de infectados, os quais já são infecciosos e podem transmitir a doença para os suscetíveis, e geralmente apresentam sintomas da doença. No grupo dos infectados (I), a taxa de saída é controlada pela taxa de recuperação ou da morte (usualmente denominada case fatality rate (CFR), que é a razão entre mortes causadas pela doença e o número de pessoas infectadas). Para o grupo dos infectados, também modelamos uma taxa que representa a contaminação de pessoas do grupo dos suscetíveis pelos infectados; a quantidade de novas pessoas expostas ao vírus também depende do número esperado de novas contaminações geradas por uma pessoa infectada, denominado basic reproduction number (\(R_0\)). O grupo dos removidos (R) tem apenas a taxa de entrada, pois uma vez dentro desse grupo não se sai mais.
Nesse post vou trabalhar com uma variação desse modelo, que denomino de SEI3R3D; os números indicam que os compartimentos representados pelas letras foram subdividios em mais subgrupos, ou seja, nesse modelo utilizo 3 grupos de infectados e 3 grupos de removidos (recuperando), além de acrescentar um novo grupo denominado de D, que representa os mortos (dead). Separei os mortos do grupo dos removidos porque recuperação e morte são consequências totalmente opostas para os infectados e existe um claro interesse analítico em separar esses casos. Os três grupos de infectados foram criados para representar três fases distintas de infecção: I0 de pessoas infectadas porém com sintomas muito leves e sem serem testadas para confirmar a infecção pelo vírus; I1 de pessoas infectadas que foram testadas devido a apresentarem síntomas de gravidade média (pelos quais elas podem até ser internadas) e I2 de pessoas infectadas que foram também testadas e apresentam sintômas graves que exigem atendimento hospitalar mais intensivo. Seguindo a mesma lógica do modelo SEIR, para uma pessoa ser internada em estado grave I2 ela tem que ter passado necessariamente pelo estágio I0, infecciosa mas sem sintomas e sem teste, e depois pelo estágio I1, com sintomas suficientes para levar a testagem. Somente entra no estágio I2 se sua condição ficar mais séria, exigindo tratamento intesivo no hospital. Só quem está no grupo I2 pode morrer, passando então para o grupo D. Ou seja, nesse modelo, o caminho que uma pessoa percorre para morrer da doença é descrito por S->E->I0->I1->I2->D.
Configurado dessa forma, o modelo SEI3R3D me permite levar em consideração as taxas de sub-notificação do Coronavírus, pois posso controlar a proporção de pessoas que saem do grupo I0 para o I1 (casos de sitomas suficientemente graves para a levar a testagem), ou então que passam diretamente do grupo I0 para o grupo de recuperados (R). Esses individuos representam os casos de sub-notificação, pois tiveram a doença porém nunca foram testados.
Para chegar ao grupo dos recuperados, é preciso antes passar primeiro por um dos grupos de pessoas em recuperação (R0, R1 e R2), os quais representam as pessoas que estão se recuperando da doença nos vários estágios de intesidade (grupos I0, I1 e I2 respectivamente)2. A motivação de criar esses três grupos em recuperação é que dessa forma posso considerar o tempo de recuperação como função da gravidade da infecção, o que me permite modelar de uma forma mais satisfatória a demanda por leitos hospitalares. Quem se recupera quando estava no grupo I0 tem uma recuperação rápida; quem se recupera depois de desenvolver sintomas mais graves demoraria mais tempo, e pode ainda precisar utilizar recursos hospitalares; finalmente, quem se recupera depois do estágio I2 provavelmente levou mais tempo de recuperação e consequentemente utilizou ainda mais recursos hospitalares do que os do grupo R1, que se recuperaram no estágio I1. Os grupos R0, R1 e R2 não se comunicam, ou seja, existem 3 caminhos distintos para a total recuperação (R) de uma pessoa infectada: I0->R0->R ou I0->I1->R1->R ou I0->I1->I2->R2->R.
Para auxiliar na explicação dos grupos do modelo e como eles se relacionam, apresento o diagrama na figura 1.
Figure 1: Diagrama de fluxo do modelo SEI3R3D
Esse modelo foi inspirado em dois modelos desenvolvidos justamente para ajudar pessoas a entender a dinâmica de transmissão do COVID-19: modelo (1) e modelo (2). Ambos esses modelos são apresentados com dashboards interativos, que permitem aos usuários alterarem os parâmetros epidemiológicos. Os parâmetros utilizados levam em consideração tanto características de transmissão da doença quanto variáveis clínicas, assim facilitando a avaliação do impacto dessas características na população alvo. O motivo pelo qual não vou disponibilizar um dashboard similar é porque esses sites já permitem flexibilidade suficiente para que uma pessoa interessada possa fazer suas próprias suposições e simulações.
Na figura 1 procurei incluir todos os parâmetros de interesse. Apesar de alguns desses serem bem técnicos, é importante destacá-los para que as possibilidades de simulação do modelo fiquem claras. Na tabela 1 abaixo, identifico cada parâmetro e incluo o intervalo de valores simulados para cada um deles, além de citar as fontes utilizadas para especificar esses valores. Alguns serão discutidos ao longo do texto, mas se você leitor achar que a tabela é longa demais e com muitos parâmetros (ou linhas) pense em quantas suposições eu estou aceitando fazer para especificar o meu modelo. São tantas, que você pode até ter preguiça de contar, e pular para a próxima seção. Porém se você não prestar atenção nas “minhas” suposições na tabela, você fará ainda mais suposições do que eu estou fazendo. É impossível prever o futuro sem fazer suposições: a dúvida consiste em quantas e quais suposições serão feitas!
| Parâmetros |
Tipo do parâmetro |
Definição | Origem |
Valores Simulados |
Fonte |
|---|---|---|---|---|---|
| \(R_0\) |
número de |
Basic reproduction number: número esperado de novas contaminações geradas por uma pessoa infectada |
parâmetro | 1, 2, 3, 4 | link |
| \(cfr\) | fração |
Case fatality rate: taxa de mortalidade de casos registrados |
parâmetro | 0.035, 0.012, 0.030, 0.019 | link |
| \(P_{sub}\) | taxa | Taxa de sub-notificação | parâmetro | 0.01, 0.30, 0.60, 0.89 | link |
| \(P_{I_{2}}\) | taxa |
Proporção dos casos que chegam no I1 que vão para o I2 |
parâmetro | 0.10, 0.23, 0.37, 0.50 | link |
| \(t_{I_{0}}\) | tempo | Tempo médio no grupo I0 | parâmetro | 6.5 | link |
| \(t_{I_{1}}\) | tempo | Tempo médio no grupo I1 | parâmetro | 2 | link |
| \(t_{I_{2}}\) | tempo | Tempo médio no grupo I2 | parâmetro | 8 | link |
| \(c_0\) | taxa | Taxa de transição de I0 para R0 | \(P_{sub}*\frac{1}{t_{I_{0}}}\) | ||
| \(c_1\) | taxa | Taxa de transição de I1 para R1 | \((1-P_{I_{2}})*\frac{1}{t_{I_{1}}}\) | ||
| \(c_2\) | taxa | Taxa de transição de I2 para R2 | \((1-cfr)*\frac{1}{t_{I_{2}}}\) | ||
| \(b_{I_{0}}\) | ajuste |
Fator de ajuste na taxa \(\beta_{0}\) para representar o isolamento social |
parâmetro | 0.80, 0.87, 0.93, 1.00 | link |
| \(b_{I_{1}}\) | ajuste |
Fator de ajuste na taxa \(\beta_{1}\) para representar o isolamento social |
parâmetro | 0.60, 0.73, 0.87, 1.00 | link |
| \(b_{I_{2}}\) | ajuste |
Fator de ajuste na taxa \(\beta_{2}\) para representar o isolamento social |
parâmetro | 0 | link |
| \(\beta_{0}\) | taxa |
Taxa de contaminação de alguém em S por alguém em I0 |
\(b_{I_{0}}*\frac{R_0}{t_{I_{0}}}\) | ||
| \(\beta_{1}\) | taxa |
Taxa de contaminação de alguém em S por alguém em I1 |
\(b_{I_{1}}*\frac{R_0}{t_{I_{1}}}\) | ||
| \(\beta_{2}\) | taxa |
Taxa de contaminação de alguém em S por alguém em I2 |
\(b_{I_{2}}*\frac{R_0}{t_{I_{2}}}\) | ||
| \(p_0\) | taxa | Taxa de transição de I0 para I1 | \((1-P_{sub})*\frac{1}{t_{I_{0}}}\) | ||
| \(p_1\) | taxa | Taxa de transição de I1 para I2 | \(P_{I_{2}}*\frac{1}{t_{I_{1}}}\) | ||
| \(p_2\) | taxa | Taxa de transição de I2 para D | \(cfr*\frac{1}{t_{I_{2}}}\) | ||
| \(d_0\) | tempo | Tempo médio de recuperação no grupo R0 | parâmetro | 1 | link |
| \(d_1\) | tempo | Tempo médio de recuperação no grupo R1 | parâmetro | 6 | link |
| \(d_2\) | tempo | Tempo médio de recuperação no grupo R2 | parâmetro | 6 | link |
| \(t_0\) | taxa | Taxa de transição do grupo R0 para R | \(\frac{1}{d_0}\) | ||
| \(t_1\) | taxa | Taxa de transição do grupo R1 para R | \(\frac{1}{d_1}\) | ||
| \(t_2\) | taxa | Taxa de transição do grupo R2 para R | \(\frac{1}{d_2}\) | ||
| \(t_e\) | taxa | Tempo médio no grupo E | parâmetro | 3.00, 4.33, 5.67, 7.00 | link |
| \(p_e\) | tempo | Taxa de transição de E para I0 | \(\frac{1}{t_e}\) | ||
| \(pop\) | população | População (total ou apenas das cidades já contaminadas) | parâmetro | 212559409, 109984605 | |
| \(casos\) | número observado | Número de casos confirmados | parâmetro | 5825 | |
| \(mortes\) | número observado | Número de mortes confirmadas | parâmetro | 202 | |
| \(n_{S}\) | número inicial | Número inicial de pessoas no grupo S | \(pop - n_{E}\) | ||
| \(n_{E}\) | número inicial | Número inicial de pessoas no grupo E | \(\frac{n_{I0}}{p_e}\) | ||
| \(n_{I0}\) | número inicial | Número inicial de pessoas no grupo I0 | \(\frac{1}{P_{sub}}\) | ||
| \(n_{I1}\) | número inicial | Número inicial de pessoas no grupo I1 | \((1-P_{I_{2}})*casos\) | ||
| \(n_{I2}\) | número inicial | Número inicial de pessoas no grupo I2 | \(P_{I_{2}}*casos\) | ||
| \(n_{R0}\) | número inicial | Número inicial de pessoas no grupo R0 | 0 | ||
| \(n_{R1}\) | número inicial | Número inicial de pessoas no grupo R1 | 0 | ||
| \(n_{R2}\) | número inicial | Número inicial de pessoas no grupo R2 | 0 | ||
| \(n_{R}\) | número inicial | Número inicial de pessoas no grupo R | 0 | ||
| \(n_{D}\) | número inicial | Número inicial de pessoas no grupo D | mortes |
Definiçao dos cenários que serão analisados
Neste post vou usar o modelo SEI3R3D para prever o número de mortes no Brasil, a CFR corrigida, a demanda máxima de leitos e o tempo necessário para sairmos da quarentena. Todos os parâmetros incluidos na tabela 1 são importantes para especificar o modelo e fazer as previsões, embora três parâmetros sejam especialmente relevantes: o fator de sub-notificação (\(P_{sub}\)), a taxa de mortalidade de casos registrados (CFR) e o número básico de reprodução (\(R_0\)). Estes se destacam tanto pela questão do impacto nas estimativas relacionadas ao vírus, quanto pela importância que têm no estudo de epidemias.
O parâmetro do número básico de reprodução (\(R_0\)) é uma métrica epidemiológica usada para descrever a contagiosidade ou transmissibilidade de agentes infecciosos. Geralmente ele é descrito como sendo o número médio de infecções secundárias produzidas por um indivíduo infectado em uma população hospedeira suscetível; é afetado por inúmeros fatores biológicos, sócio-comportamentais e ambientais que controlam a transmissão de patógenos, e raramente pode ser observado diretamente. Por esse motivo, o \(R_0\) geralmente é estimado utilizando vários tipos de modelos matemáticos complexos. Apesar de toda essa complexidade com relação a esse parâmetro, ele é interessante porque permite que suposições sobre o impacto da quarentena na disseminação do Coronavírus sejam facilmente aplicadas no modelo utilizado. Tomando como valor de referência a estimativa do \(R_0\) em Wuhan, na China, antes das medidas de supressão adotada pelo governo chinês, podemos estimar o impacto das medidas de quarentena aplicando uma redução percentual sobre esta estimativa. A grande maioria das publicações que eu encontrei colocam o valor de \(R_0\) como sendo entre 1.5 e 4.5. Neste post, usarei o valor de referência para \(R_0\) como sendo 3. Uma vez que várias medidas de contenção estão sendo tomadas, também analisarei dois outros cenários para simular o impacto destas medidas: uma redução 33% considerando \(R_0 = 2\) e outra redução ainda maior, de 66%, com \(R_0 = 1\).
A taxa de mortalidade de casos (CFR) é uma medida da gravidade de uma doença e é definida como a proporção de casos de uma doença ou condição que são fatais dentro de um tempo especificado. Altos valores da CFR também podem refletir acesso limitado a cuidados de saúde adequados por pessoas mais vulneráveis e também insuficiências nos sistemas de saúde, como a capacidade limitada dos mesmos. Superficialmente, esta taxa parece ser simples e intuitiva, porém ela é bastante afetada pela sub-notificação do número de pessoas infectadas pela doença. O fato de muitas pessoas com sintomas mais leves não serem testadas afeta diretamente a estimativa da letalidade de uma doença, não só reduzindo o denominador da taxa, como também levando em consideração apenas casos mais graves da doença, condição esta que geralmente aumenta a chance de óbito de uma pessoa infectada.
Pensando especificamente no caso do Coronavírus, sabe-se também que esta taxa é muito diferente para alguns sub-grupos da população, como pessoas de certos grupos etários (e também pessoas com outras condições de saúde pré-existentes). A doença é muito mais letal para pessoas idosas, com mais de 60 anos, do que para o resto da população. Para definir os diferentes cenários no que se refere ao CFR, utilizaremos o caso da Itália como referência. Para muitos, esse país é visto como o lugar mais impactado pelo Coronavírus, tanto pela idade avançada da população, quanto pelo colapso do sistema de saúde: até o dia 30 de março foram registradas 10.781 mortes no país. Na tabela 2 abaixo, apresento a distribuição da população da Itália, do Brasil e dos EUA por 10 faixas etárias, e também mostro a CFR estimada na Itália para cada uma dessas faixas (coluna destacada em cinza). Com esses valores, é possível calcular a CFR nacional para esses três países (linha destacada em laranja), ajustada pela distribuição etária do país. Note que a CFR nacional estimada para a Itália é quase 2.5 vezes maior do que a do Brasil porque naquele país quase 30% da população tem 60 anos ou mais, embora no Brasil esse percentual seja de apenas 14%. A CFR estimada para os EUA fica entre os dois outros países. Vamos considerar nas simulações esses 3 valores de CFR, além de incluir um quarto valor, de 3,5%, que representa a taxa de morte observada para as pessoas comprovadamente infectadas no Brasil até o dia 31 de março. A fonte para as estimativas italianas por faixas etárias é esse estudo da Imperial College. A fonte para a distribuição etária dos três países foi essa.
|
Faixas de Idade |
CFR por faixa |
% população Itália |
% população Brasil |
% população EUA |
|---|---|---|---|---|
| 0-9 | 0.0% | 8.4% | 13.7% | 12.6% |
| 10-19 | 0.0% | 9.6% | 14.7% | 13.0% |
| 20-29 | 0.0% | 10.3% | 16.0% | 13.7% |
| 30-39 | 0.2% | 11.7% | 16.2% | 13.1% |
| 40-49 | 0.2% | 15.3% | 13.9% | 12.4% |
| 50-59 | 0.8% | 15.5% | 11.5% | 13.4% |
| 60-69 | 2.7% | 12.2% | 7.9% | 11.5% |
| 70-79 | 10.8% | 9.9% | 4.1% | 6.6% |
| 80+ | 19.3% | 7.2% | 2.0% | 3.6% |
| CFR Total | 3.0% | 1.2% | 1.9% |
O último parâmetro a ter destaque é o fator de sub-notificação (\(P_{sub}\)). Existem alguns estudos que tentam estimar qual seria a incidência real do Coronavírus. Aqui vou levar em consideração apenas esse estudo, no qual estima-se que a taxa de sub-notificação no Brasil seja entre 86% e 91.1%, com estimativa pontual de 89%. Para os nossos cenários, com relação ao fator de sub-notificação, utilizaremos os seguintes valores: 1%, 30%, 60% e 89%, representando cenários nos dois extremos de sub-notificação, como também dois cenários intermediários.
Os cenários considerados incluem não somente variações desses três parâmetros, como também variações para os valores de todos os outros parâmetros descritos na tabela 1. Para cada um foram utilizados quatro valores igualmente espaçados, percorrendo toda a gama de valores citados na tabela.
Há também um outro parâmetro relevante para as inclusão em nossas simulações: o tamanho da população considerada. Utilizarei dois tamanhos populacionais diferentes: um considerando toda a população brasileira, estimada como sendo 212,559,409 em 2019, e outro considerando uma população menor (apenas os residentes de municípios que têm pelo menos um caso comprovado de Coronavírus). Até o dia 31 de março, 402 municípios brasileiros tinham pelo menos um caso confirmado; o total populacional desses municípios é de 109,984,605. A motivação de adicionar mais esse critério é porque a suposição desse cenário é mais tangível: se as medidas de contenção adotadas pelo governo forem efetivas, poderíamos supor que nenhum novo município seria atingido. Pode parecer uma suposição forte, porém é mais intuitiva do que supor uma redução percentual sobre o \(R_0\) (algo que tem pouca conexão com a realidade). A fonte dos dados utilizados para contabilizar o número de municípios contaminados é o site Brasil.io.
É importante mencionar que a condição inicial de cada modelo supõe que o número de mortos e infectados testados coincide com as valores atuais do país. As outras quantidades populacionais são iniciadas com valores que são compatíveis com a quantidade de infectados e mortos, sendo que esses valores são calculados utilizando os diferentes parâmetros de cada cenário, conforme especificado na tabela 1. Ao total foram simulados 32.768 cenários diferentes, os quais permitirão uma visão bem abrangente do impacto das suposições nas estimativas do modelo, principalmente no que se refere ao número de mortes, à CFR corrigida, à demanda máxima de leitos e ao tempo necessário para sairmos da quarentena.
O impacto da sub-notificação da incidência do vírus
Para essa primeira análise, vamos nos limitar a comparar dois cenários idênticos, com exceção do parâmetro de sub-notificação, apenas com o objetivo de mostrar como a dinâmica do vírus é modelada. Na figura 2 mostramos os resultados com a sub-notificação limitada a 1%, e considerando a população de todas as cidades do Brasil. No eixo vertical (y) representamos a quantidade de pessoas, e no eixo horizontal (x) representamos o tempo. As cores do gráfico indicam o grupo/compartimento. Nesse gráfico simulamos o comportamento do vírus na população brasileira para o período de 2 de março a 30 de agosto. Para entender a dinâmica do modelo, perceba como inicialmente só existem Suscetíveis (S; em vermelho). Com o passar do tempo, o número de suscetíveis vai dimunindo, conforme a população vai passando para os outros estágios da doença. Os suscetíveis sumirão da população depois que o vírus infectar toda a população. Note também que o o número de Recuperados (R; em rosa), e o número de Mortos (D; na parte inferior do gráfico em rosa escuro) nunca diminui. Isso ocorre porque uma vez entrando nesses grupos, não há possibilidade de sair. Todos os outros grupos são temporários, no sentido de que pessoas passarão por eles, mas depois irão para outro grupo; por isso que no começo e no final do gráfico esses grupos não existem.
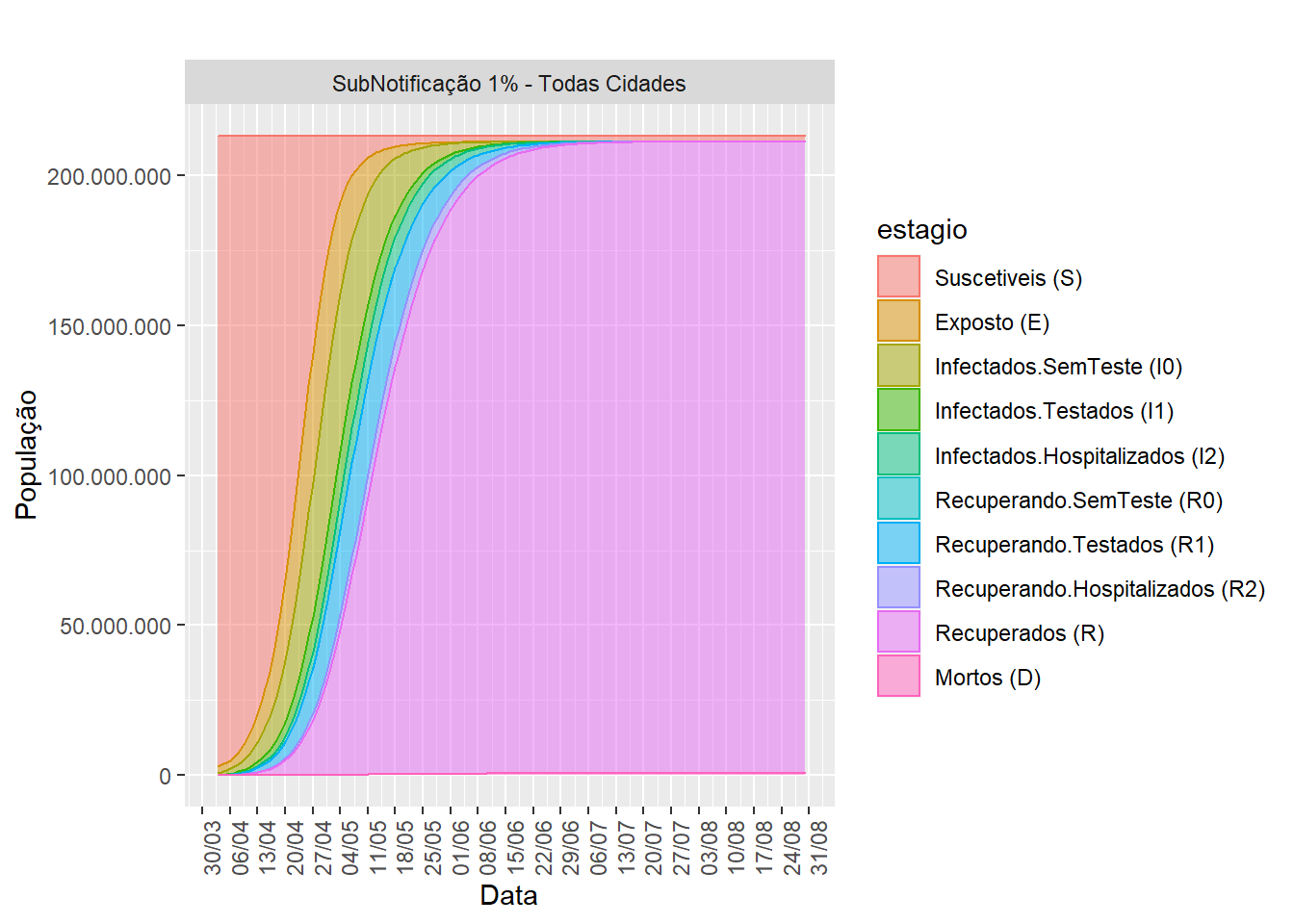
Figure 2: Dinâmica populacional do modelo SEI3R3D
A informação contida na figura 3 é igual aquela da figura 2, porém mostrando apenas a parcela da população que foi infectada pelo vírus e testada. Os mortos no gráfico, na parte inferior do gráfico em rosa, ficam mais visíveis por causa da escala. Também é possível observar que a curva representando os Infectados Hospitalizados (R2; em azul), é mais achatada do que as curvas representando os outros grupos. Isso ocorre porque é mais difícil (e mais demorado) para sair desse grupo do que dos outros grupos. Note também que em determinado momento do processo, existem apenas mortos; os outros grupos deixaram de existir na população. Quando isso ocorre quer dizer que o vírus foi naturalmente eliminado da população e este seria, teoricamente, o momento ideal de terminar a quarentena.
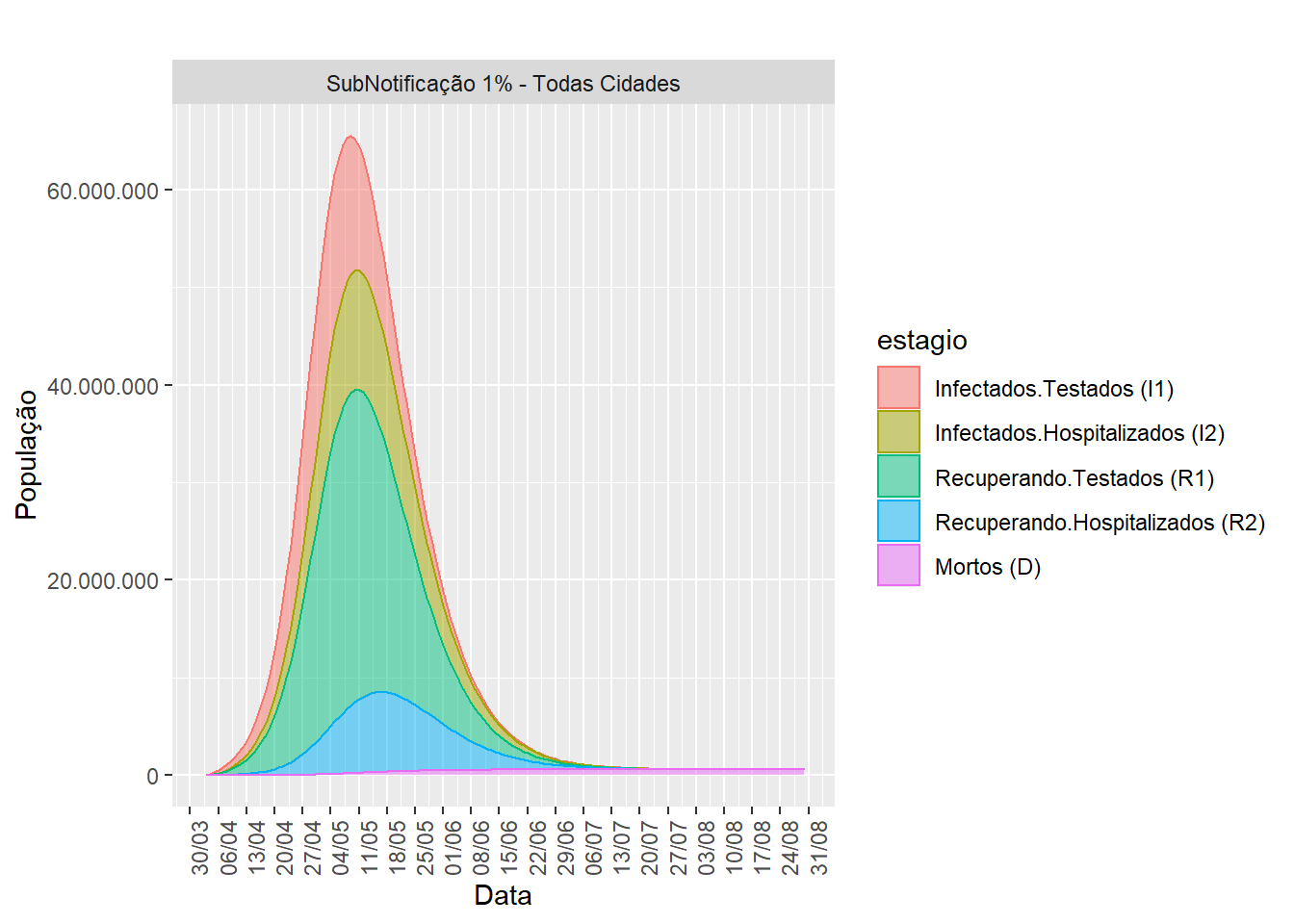
Figure 3: Dinâmica populacional do modelo SEI3R3D - Infectados Testados
Agora vamos ver o que acontece quando existe uma quantidade significativa de sub-notificação. Na figura 4 mostramos apenas o número de Infectados.Hospitalizados (I2), porém consideramos quatro cenários distintos: dois com pouca sub-notificação (1%) considerando tanto todas as cidades do Brasil quanto somente as cidades com casos confirmados, e outros dois equivalentes com relação a todos os parâmetros e suposições, porém com muita sub-notificação (89%). O interesse analítico desses cenários é entender o impacto da sub-notificação. Percebe-se que se a sub-notificação é alta (curvas azul e roxa), o pico de hospitalizações é menor, e a demanda por leitos é mais espalhada no tempo, bem menos concentrada do que nos casos com pouca sub-notificação (curvas vermelha e verde). Ou seja, se existe muita sub-notificação, existem muito mais pessoas infectadas na população, só que elas não são testadas para confirmar que têm o vírus. Isso quer dizer que uma grande parcela das pessoas no grupo I0 irá direto para recuperação (R0) pois não terá agravamento dos seus sintomas; consequentemente, uma parcela bem menor dessas pessoas irá para o grupo (I1) se comparado ao cenário com pouca sub-notificação. Isso quer dizer que bem menos pessoas serão hospitalizadas, e a demanda por leitos será, na verdade, bem menor do que esperávamos considerando as estatísticas enviesadas calculadas supondo que não havia sub-notificação. Nos cenários apresentados aqui, a CFR modelada foi de 1,2%, ou seja, essa é a taxa de morte entre as pessoas infectadas que foram testadas. Porém, ajustando essa taxa pela sub-notificação de 89%, descobrimos que a taxa de morte entre todos os infectados e não somente os testados é, na realidade, de 0,1%, quase 10 vezes menor.
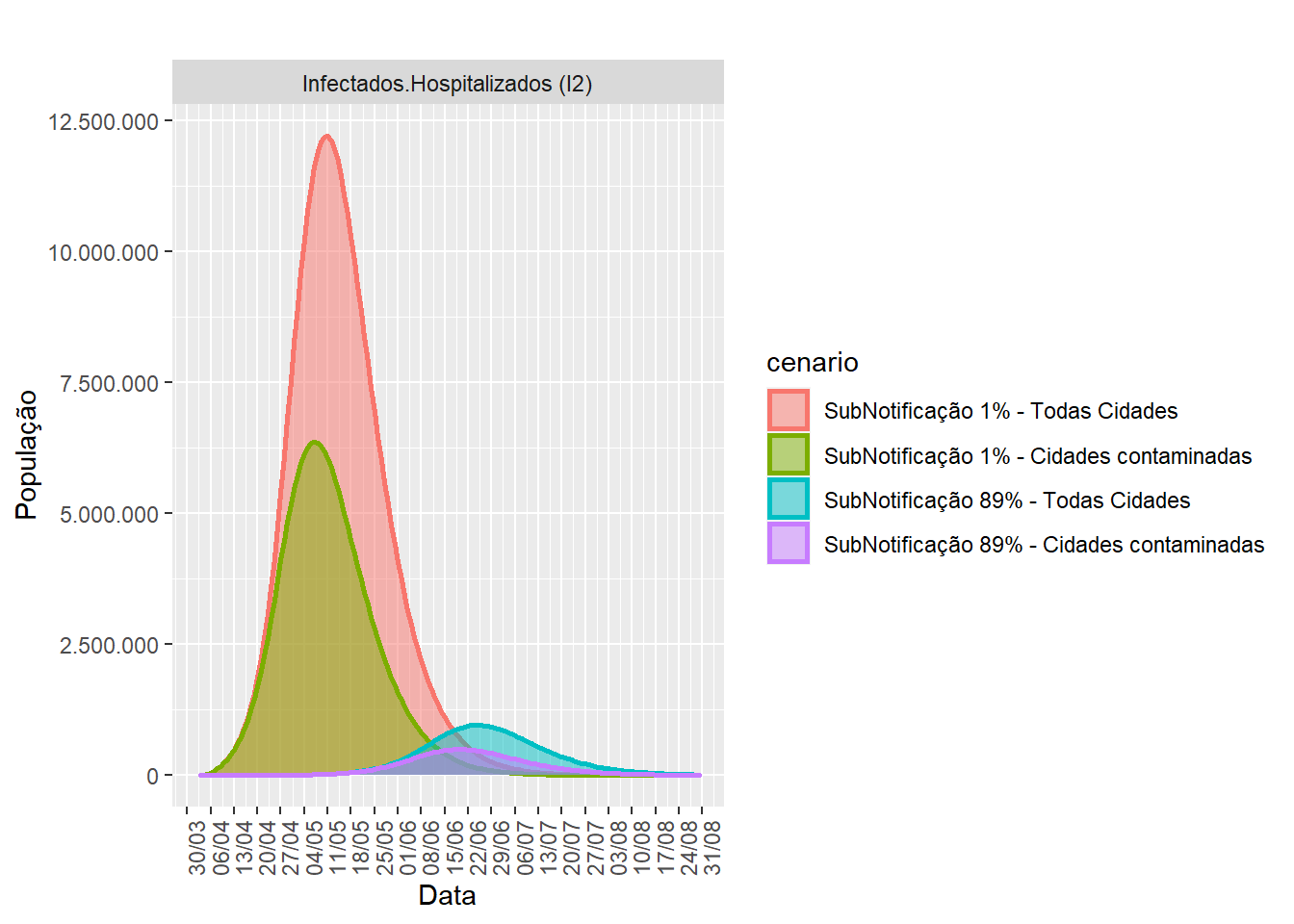
Figure 4: Comparando cenários com e sem sub-notificação
Análise de todos os cenários considerados
Nessa seção irei analisar os resultados dos mais de 36 mil cenários considerados. Com esta análise tentarei responder a três perguntas importantes: qual será o número de mortos, qual será a demanda máxima de leitos hospitalares e qual seria data do final da quarentena. Utilizarei duas estratégias distintas. A primeira, com o objetivo de estimar um intervalo razoável para cada previsão, consiste em ordenar todas as previsões de todos os cenários, e escolher um intervalo de valores que inclua a previsão do modelo em 50% dos cenários, excluindo os 25% de cenários mais otimistas e os 25% mais pessimistas. Dessa forma sabemos que mesmo fazendo muitas suposições diferentes, o intervalo de predição é compatível com metade dos cenários considerados.
A segunda estratégia tem como objetivo obter uma estimativa pontual para as previsões. Calculo o erro médio absoluto (EMA) comparando as previsões do modelo em cada cenário com o número real de mortes diárias acumuladas no Brasil desde o primero caso comprovado até o dia 1 de abril. A previsão final é calculada como sendo a mediana dos 100 cenários com menor erro.
Previsões do número total de mortes
Na figura 5 apresentamos um histograma com as previsões do número de mortes de todos os cenários estudados. No eixo vertical (y) são contabilizados a quantidade de cenário com aquela faixa de previsões, e o eixo horizontal (x) representa a quantidade de mortes previstas. A curva vermelha sobreposta ao gráfico mostra o percentual acumulado de cenarios que tem uma previsão de mortes menor ou igual aquele ponto. Nesse gráfico incluímos o intervalo com as previsões mais plausíveis (em cinza escuro), que apontam um número de mortes entre 100 mil e 750 mil, bem como uma previsão pontual (em azul), de 477 mil mortes. Note que a amplitude das previsões do número de mortes em todos os cenários vai de menos de 30 mil casos até mais de 3,5 milhões de casos, deixando bem claro o possível impacto das suposições nas previsões!
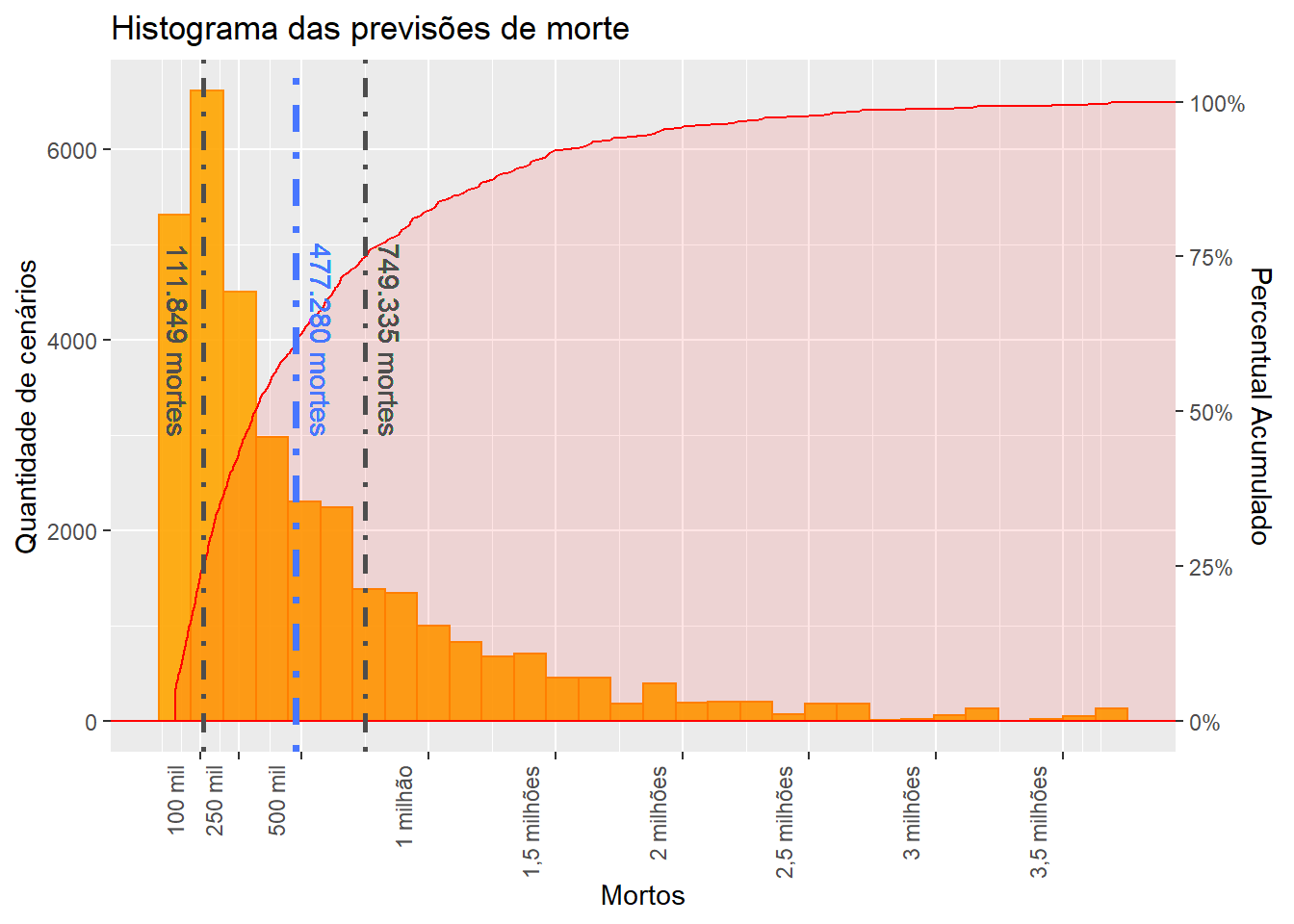
Figure 5: Projeções do número de mortes em todos os cenários
É importante ressaltar que talvez essa forma de encontrar uma previsão pontual não seja a mais sensata, pois apesar de encontrarmos uma previsão que minimiza o erro de predição, estamos considerando diversos cenários que podem ser completamente irreais, como supor que não existe sub-notificação, que o \(R_0 = 4\) e que o \(CFR = 3,5\)%. Para enfatizar que talvez um melhor caminho a seguir fosse excluindo alguns cenários bastante improváveis, mostramos a figura 6. Essa figura tem a mesma informação da figura 5, porém sub-dividida em 8 painéis diferentes, mostrando todos os diversos cruzamentos de cenários com relação aos quatro níveis de sub-notificação e aos dois tamanhos populacionais (todas as cidades, ou apenas aquelas cidades já contaminadas). Fica evidente nessa figura que quanto maior a taxa de sub-notificação, menor é o número de mortes prevista. E obviamente se considerarmos apenas as cidades já contaminadas a previsão também é menor. Uma alternativa para encontrar uma estimativa pontual poderia ser escolher apenas cenários do painel que fosse mais realista no momento em que a previsão estiver sendo feita. Outra alternativa, talvez ainda melhor, seria ao invês de dar a mesma chance para cada cenário, dar probabilidades maiores para aqueles cenários que epidemiologistas considerem mais prováveis, análogo a utilizar uma distribuição à priori informativa nos parâmetros do modelo.
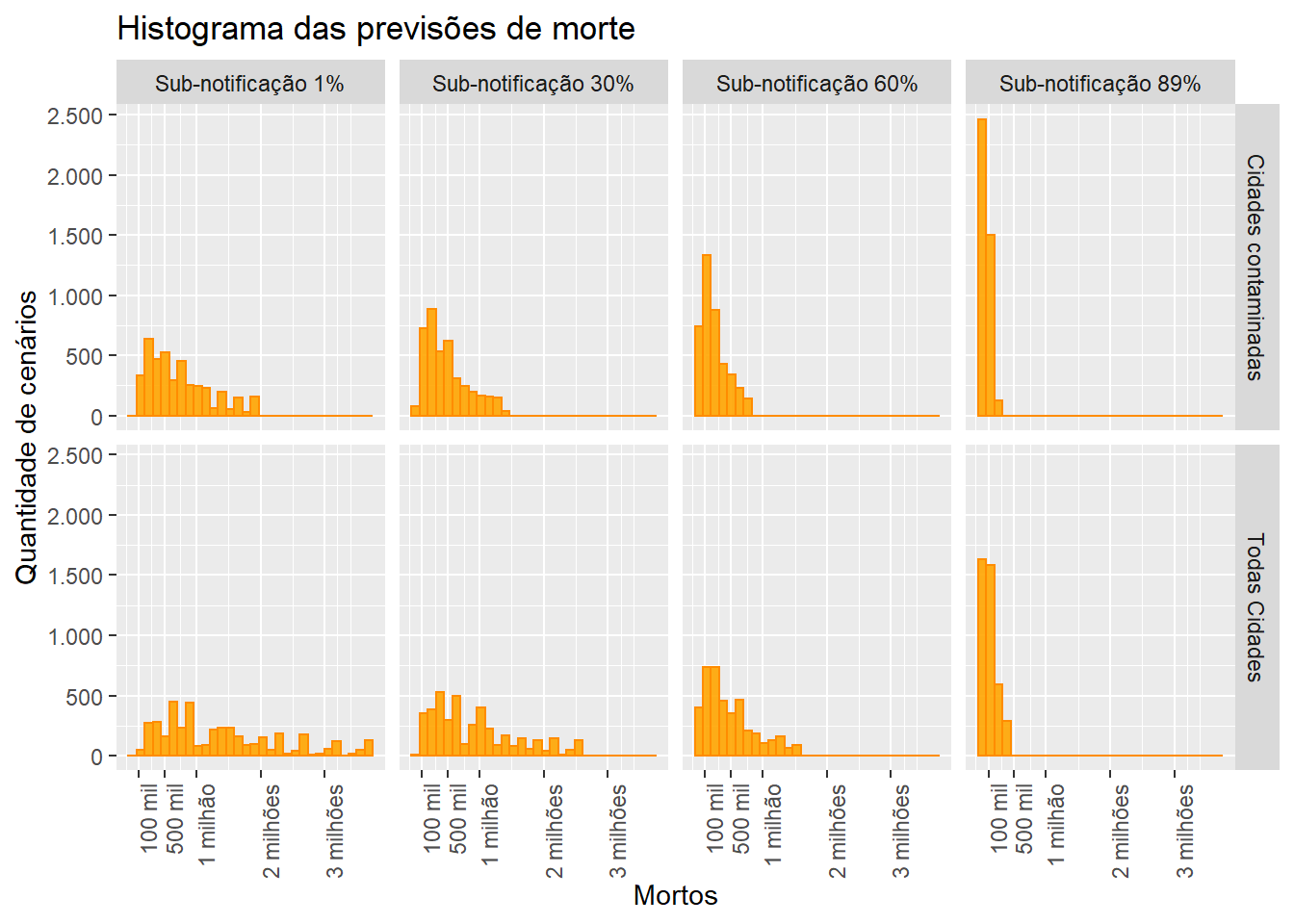
Figure 6: Projeções do número de mortes - Painéis
Previsão da demanda de leitos hospitalares e final da quarentena
Para fazer as outras previsões de interesse, utilizaremos a mesma estratégia descrita anteriormente para encontrar os intervalos e uma previsão pontual. Com relação à demanda hospitalar, para a analise apresentada aqui, iremos considerar conjuntamente os seguintes grupos: “Infectados e Hospitalizados (I2)” e “Recuperando e Hospitalizados (R2).” Dessa forma vamos supor que o tipo de leito hospitalar/equipamento necessário para pessoas nesses dois grupos é a mesma; nessa análise não estamos considerando pessoas nos grupos I1 e R1 de infectados que apenas tiverem sintômas de média gravidade. Claramente essa é uma suposição forte, porém estou fazendo-a apenas para simplificar a análise apresentada aqui.
Com relação a quarentena, ela se encerrará quando não houver mais pessoas em nenhum dos três grupos de infectados (I0, I1, I2), pois segundo o nosso modelo somente pessoas nesses grupos podem infectar outras pessoas. Também vou considerar um segundo cenário para determinar o tempo de quarentena, menos extremo, onde é considerado um risco aceitável de haver ainda 10.000 pessoas potencialmente infecciosas. A motivação para escolher esse segundo cenário vem do fato que, no mundo real, não há como saber se ainda existem pessoas infecciosas, e em termos práticos temos que aceitar que ao deixar a quarentena, teremos que correr riscos. As previsões são apresentadas na tabela 3.
| Previsão |
Intervalo Inferior |
Previsão pontual |
Intervalo Superior |
|---|---|---|---|
|
Demanda máxima de leitos |
5.054.429 | 9.472.611 | 16.102.672 |
|
Final da quarentena (0 infecciosos) |
2020-09-01 | 2020-09-07 | 2020-09-13 |
|
Final da quarentena (10.000 infecciosos) |
2020-06-10 | 2020-06-20 | 2020-06-30 |
Conclusão
Quando eu comecei a pensar sobre o que escrever este post, eu havia decidido não fazer uma previsão do número de mortes causadas diretamente pelo Coronavírus, até porque agora vejo pouca utilidade nas previsões sobre o número de mortes que serão causadas pelo vírus, visto que o Coronavírus já está sendo tratado com bastante seriedade pela sociedade e virtualmente todos os recursos possíveis já estão sendo alocados na sua contenção.
Meu plano inicial era obrigar você, leitor, a ter que fazer as suas próprias suposições para obter uma previsão, para que você sentisse na pele como é difícil tentar prever o futuro, e como é impossível fazê-lo sem fazer inúmeras suposições. Queria que você compartilhasse da incerteza que os cientistas também sentem ao tentar prever o futuro, e da dificuldade em compreender o impacto que esse vírus terá na nossa sociedade. Porém ao escrever o post, senti que dado o contexto atual, não era o momento de ensinar uma lição a ninguém, mas sim o momento de tentar enxergar a luz no final do túnel. A lição que nós aprenderemos será dada pelo futuro! Porém, deve ficar claro ao leitor que não sabemos o futuro, e não devemos nunca esquecer que previsões são apenas previsões, que podem estar certas ou erradas. Para enfatizar esse ponto, vale a pena ressaltar que, nos cenários analisados nesse post, a amplitude das previsões do número de mortes vai de menos de 30 mil casos até mais de 3,5 milhões de casos, deixando claro tanto o possível impacto das suposições nas previsões, quanto a incerteza gerada por elas na tentativa de prever o futuro.
Escrevi um post no ano passado sobre a falácia do pior cenário imaginável, no qual discuto a diferença entre um cenário imaginável, e um cenário possível. Um vez feita a análise que eu apresentei neste post que você está lendo agora, acredito que os cenários que foram apresentados pelos epidemiologistas são possíveis, o que é muito importante, pois cenários apenas imagináveis não são úteis. Os cenários apresentados, porém, provavelmente estão mais próximos ao extremo do pior cenário possível do que ao mais provavél.
É importante perceber que, dado a dificuldade em enxergar o que ainda está por vir, é comum trabalhar com o pior cenário possível. É uma estratégia utilizada frequentemente. É uma forma dos cientistas forçarem governos, através da opinião pública, a agir. Como indivíduo, entretanto, eu não gosto desta estratégia; não gosto de ser pressionado por esse tipo de argumento. Eu não gosto que me digam o que eu devo fazer. Eu espero que você me diga a sua opinião, e os seus argumentos. E eu vou me esforçar para entendê-los. Porém eu prefiro decidir por mim mesmo. Acredito que todos temos o direito (e o dever) de ter as nossas próprias opiniões!
Porém como parte de um coletivo maior, de uma sociedade, consigo entender o uso desse tipo de estratégia que busca forçar as pessoas a agirem de uma forma que talvez seja melhor para todos, mesmo que elas não queiram ou não saibam. Mas esse caminho é potencialmente perigoso. Não há dúvida; muitas formas opressoras de governar começaram usando alguma variação desse tipo de argumento! Entretanto, ignorando esse risco, entendo que no curto prazo, todos estarmos em quarentema de forma preventiva de fato irá salvar vidas.
Por mais que a ocorrência do vírus não seja nossa culpa, não podemos esquecer que nós estamos optando por entrar em quarentena, abrindo mão de diversos direitos no presente, com o intuíto de evitar um futuro potencialmente tenebroso, onde milhões de pessoas, principalmente idosos, morreriam. Porém nós não temos certeza se esse futuro tenebroso iria de fato ocorrer. E agora, nunca saberemos, pois as medidas preventivas que tomamos com certeza estão alterando o futuro que um dia iremos vivenciar. Nós acreditamos que estamos vencendo a natureza, sendo espertos, evoluindo, salvando a nós mesmos.
Se já era extremamente difícil prever o futuro antes da quarentena, agora que estamos intencionalmente alterando nosso modo de vida, me parece mais impossível ainda avaliar o que nos espera. Será que estamos tomando as melhores decisões? Tenho tantas dúvidas sobre a decisão a ser tomada nesse momento que quase não consigo distinguir entre curto, médio e longo prazo! Porém acredito que seja exatamente sobre isso que temos que pensar agora. A quarentena já foi implementada, já é uma realidade. Agora temos que pensar em como e quando vamos sair dela.
Tenho pensado muito sobre como devemos agir para sair da quarentena. Quando começaremos a pensar no médio prazo? Pelas minhas simulações, fica claro que se fossemos oniscientes, e esperássemos até não existir absolutamente ninguém infeccioso, a quarentena poderia facilmente durar até Setembro, ou até mais que isso. Porém no mundo real, nunca saberemos de fato se o vírus foi eliminado da população. Será que ele precisar ser? Vamos sair da quarentena todos JUNTOS? Ou deixamos os idosos mais tempo em isolamento, enquanto o resto da sociedade volta a funcionar mais rapidamente? Começamos permitindo que pelo menos as crianças voltem as escolas? Me parece que o mais sensato será transformar gradualmente o isolamento horizontal em isolamento vertical.
O Coronavírus fez a morte parecer algo muito mais tangível para a grande maioria das pessoas. Ela ficou mais próxima, mais real, mais imediata. Agora parece que todas as nossas decisões são sobre viver ou morrer. E quase todo mundo faria qualquer coisa para não morrer. Por isso é muito difícil ser racional durante essa pandemia. Porém me parece que se existe algum momento na nossa história em que é importante tentar conciliar nosso lado emocional com nosso lado racional, é este! Não acredito que seja possível sair da quarentena sem correr riscos. Na verdade acredito que já estejamos correndo riscos, pois estamos priorizando apenas o curto prazo, mas tenho sérias dúvidas se as estratégias adotadas de isolamento horizontal, no final das contas, são as melhores para a nossa sociedade como um todo. Não me refiro ao valor econômico da vida de uma pessoa, ou de um idoso. Penso mais sobre quantas vidas serão salvas no curto prazo versus no longo prazo. Ou quantos anos a mais de vida que serão poupados, vividos e aproveitados pelas pessoas. Quanto mais tempo ficarmos em quarentena, mais impactamos todos os outros aspectos da nossa vida e da sociedade. Cada vez mais me convenço que o fator que será determinante para avaliar se a quarentena horizontal foi uma boa medida de contenção será a forma e a velocidade que saíremos dela.
Eu, particularmente, já estava numa fase de pensar muito sobre a proximidade da “morte”, por motivos diferentes, alguns superficiais e outros mais profundos. Percebi que nunca mais poderei jogar bola como fiz a minha vida toda, porque meu joelho não aguenta mais; o que me causava uma alegria imensa agora me causa dor. Perdi algumas pessoas próximas, que tinham um tesão invejável pela vida. Depois do Coronavírus, obviamente, até por ficar mais tempo sozinho, longe dos meus amigos, tenho pensando ainda mais sobre o assunto. E cheguei a uma conclusão incrivelmente óbvia: todos vamos morrer um dia, por um motivo ou outro! E é por isso que não é possível reduzir o risco de morrer a zero: as causas de morte competem entre si. Não podemos olhar uma única causa de morte isoladamente e achar que se minimizarmos a chance de morrer por esse motivo estamos diminuindo nossa chance total de morrer. Nós temos que olhar todas as causas de morte conjuntamente. O que tem que ser reduzida é a nossa chance total de morte e não apenas aquela causada por um motivo específico. Se o objetivo é adiar a morte, não podemos subestimá-la desse jeito tratando-a como se fosse unidimensional, pois “ELA” sabe que, uma dia ou outro, vai pegar cada um de nós. Inclusive, ela pega aproximadamente 150 mil pessoas por dia no mundo.
Para finalizar esse post, segue uma citação bastante interessante do famoso escritor de ficção científica Isaac Asimov, sobre a importância das suposições:
“Suas suposições são suas janelas para o mundo. Limpe-as de vez em quando, ou a luz não entrará.”
É possível argumentar que os modelos mais importantes foram aqueles utilizados por Alan Turing para quebrar códigos utilizados pelo nazistas para se comunicar durante a segunda guerra mundial, os quais estima-se salvaram milhões de vida; porém só o futuro dirá quais modelos foram mais importantes. Essa história é contada no filme O jogo da imitaçao, e se você não o assistiu ainda, é uma ótima sugestão de algo para fazer nesses tempos de quarentena…↩︎
Note que, infelizmente, o grupos das pessoas em recuperação R0 tem uma notação muito similar ao parâmetro \(R_0\), que indica o número esperado de novas contaminações geradas por uma pessoa infectada (basic reproduction number). Cuidado para não confundir essas duas quantidades.↩︎